深度解读 — 2026年春季开源LLM架构全景
深度解读 — 2026年春季开源LLM架构全景
原文:A Dream of Spring for Open-Weight LLMs: 10 Architectures from Jan-Feb 2026 作者:Sebastian Raschka | 发表于 2026-02-25(含后续更新至 Mar 6)
速查卡
| 维度 | 内容 |
|---|---|
| 一句话总结 | 对 2026 年 1-2 月发布的 10+ 个主流开源 LLM 进行架构级别的横向对比,揭示当前开源模型的技术趋势 |
| 大白话版 | 最近两个月冒出了一大堆开源大模型,Raschka 把它们的”骨架”拆开来一个个比较,告诉你谁抄了谁的作业、谁做了创新 |
| 覆盖模型 | Trinity Large 400B, Kimi K2.5 1T, Step 3.5 Flash 196B, Qwen3-Coder-Next 80B, GLM-5 744B, MiniMax M2.5 230B, Nanbeige 4.1 3B, Qwen3.5 397B, Ling 2.5 1T, Tiny Aya 3.35B, Sarvam 30B/105B |
| 重要性 | A(必读) — 目前最全面、最技术化的开源 LLM 架构横评 |
总览:为什么这篇文章值得深读
2026 年开头两个月,开源 LLM 领域经历了一波密集发布。Raschka 不是简单罗列参数表,而是逐一画出每个模型的架构图,做并排对比,解释每个设计选择背后的技术原因。对于想理解”当前 LLM 架构到底在往哪走”的人来说,这可能是最好的一站式参考。
1. Arcee AI Trinity Large(400B, 1月27日)
Trinity Large 是 Arcee AI 发布的 400B 参数 MoE 模型(13B 活跃参数),还有 Mini(26B/3B 活跃)和 Nano(6B/1B 活跃)两个小版本。
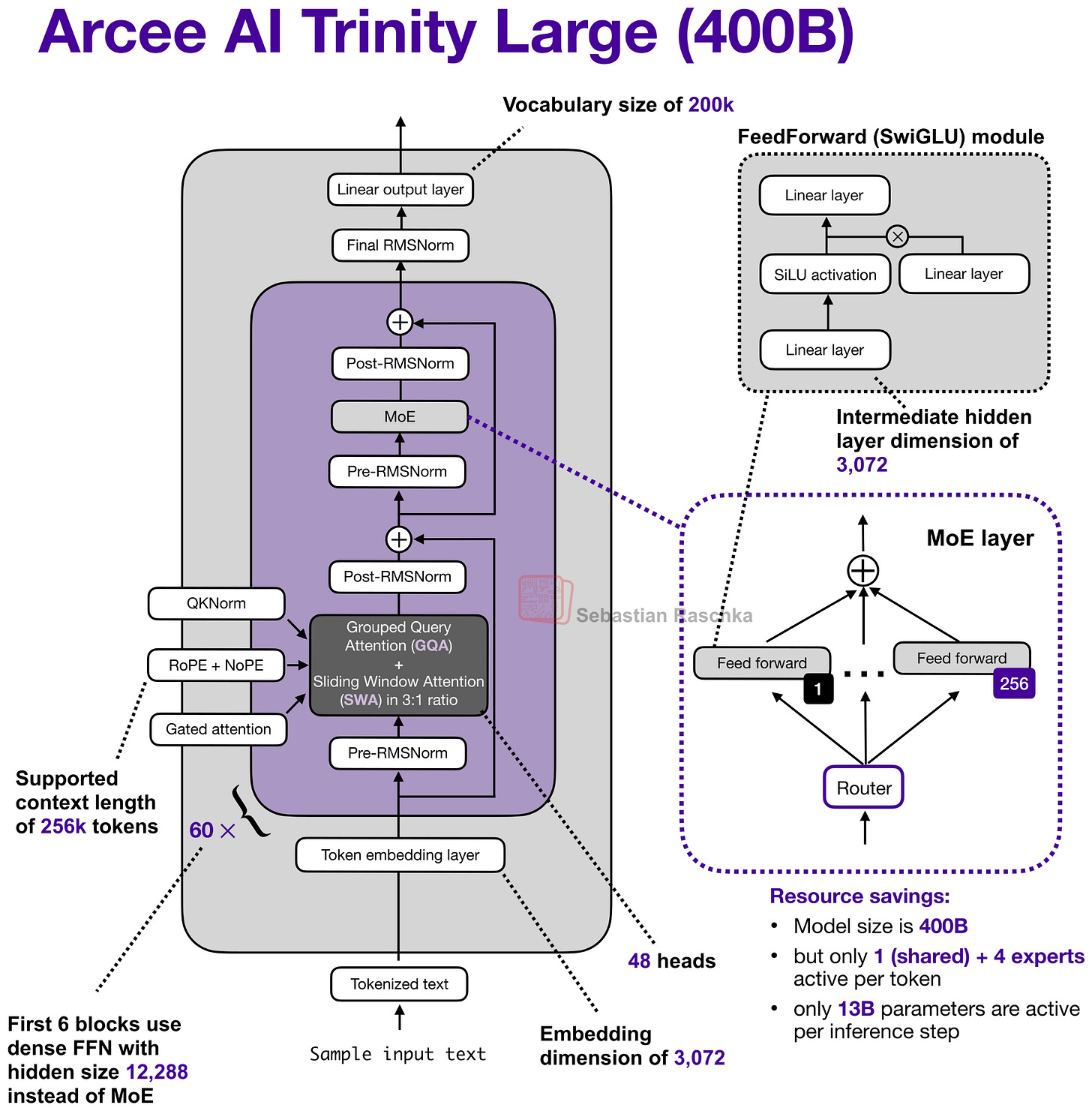
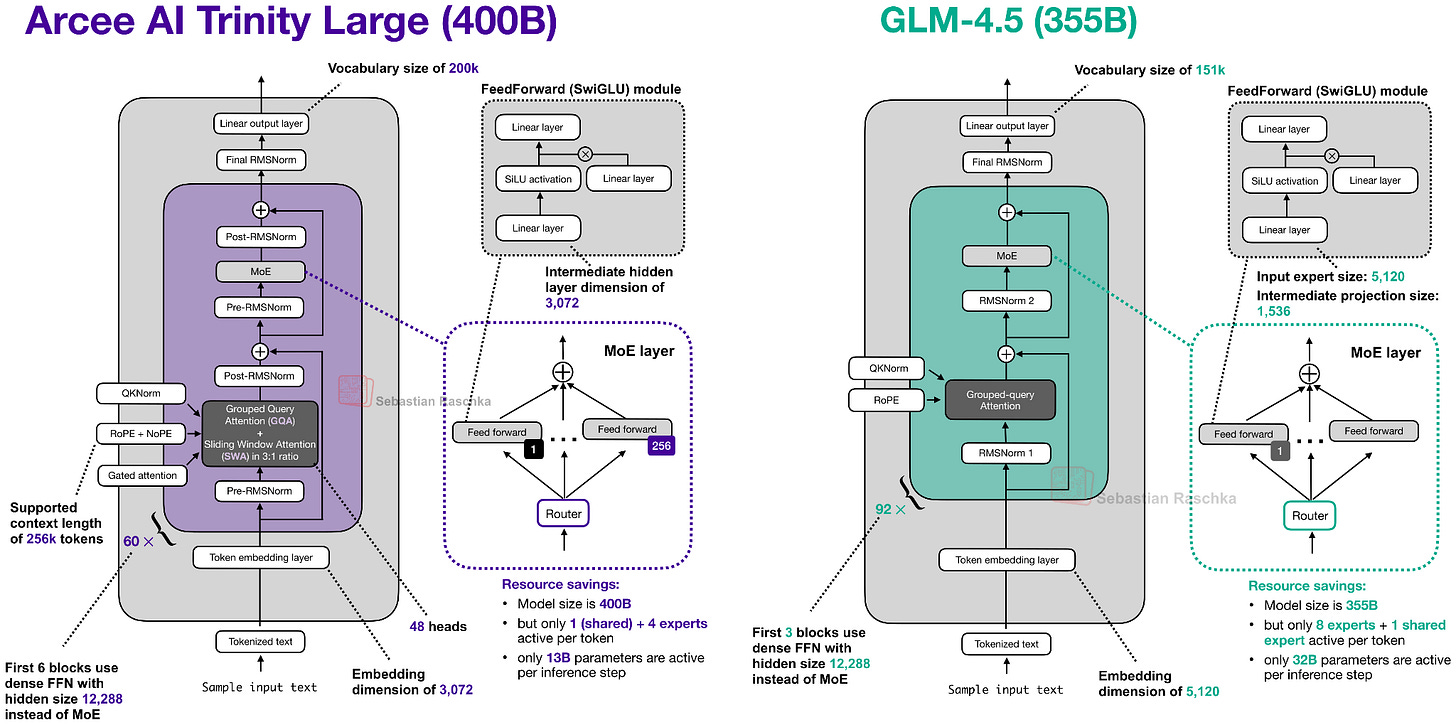
与 GLM-4.5 的对比揭示了 Trinity 的几个关键架构创新:
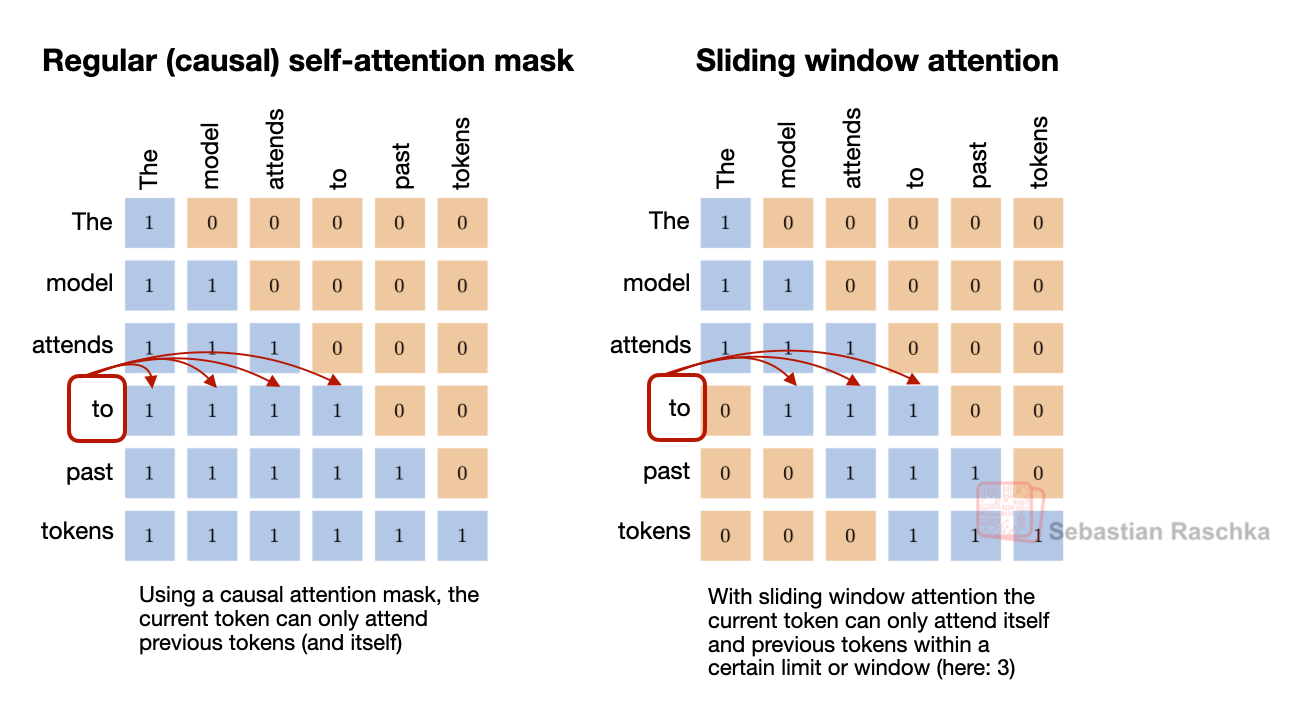
滑动窗口注意力(SWA)
Trinity 采用交替的 local:global 注意力层,比例为 3:1,滑动窗口大小 4096(类似 OLMo 3)。在 SWA 中,每个 token 只关注最近 t 个 token(比如 4096),而不是整个输入序列(可能高达 256,000 token),将每层注意力成本从 O(n²) 降到 O(n·t)。
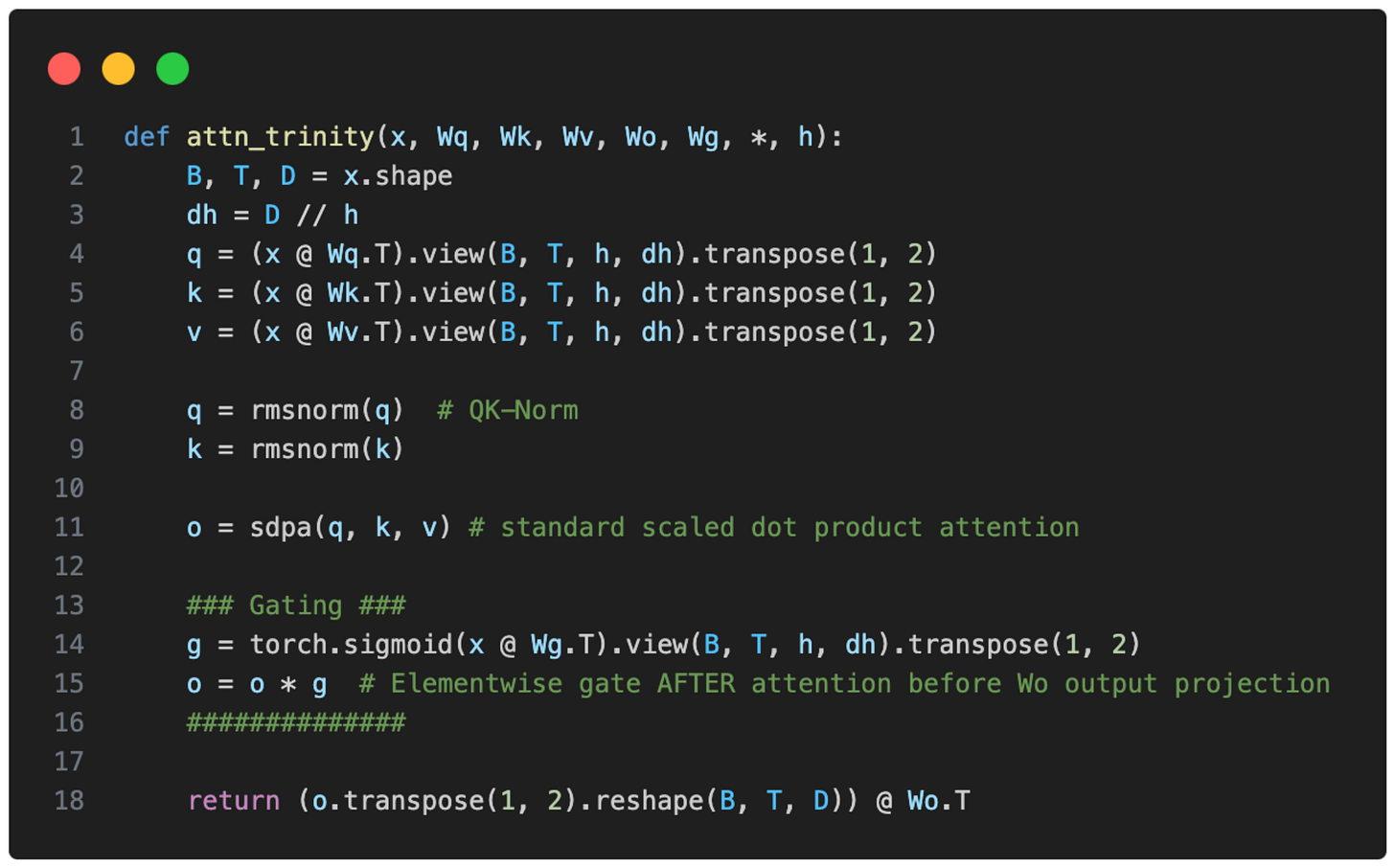
门控注意力机制
Trinity 在标准 scaled dot-product attention 之后加了一个逐元素门控(sigmoid 控制),在输出线性投影之前缩放注意力结果。这种设计:
- 减少 attention sink(注意力无意义地集中在某些 token 上)
- 改善长序列泛化
- 增强训练稳定性
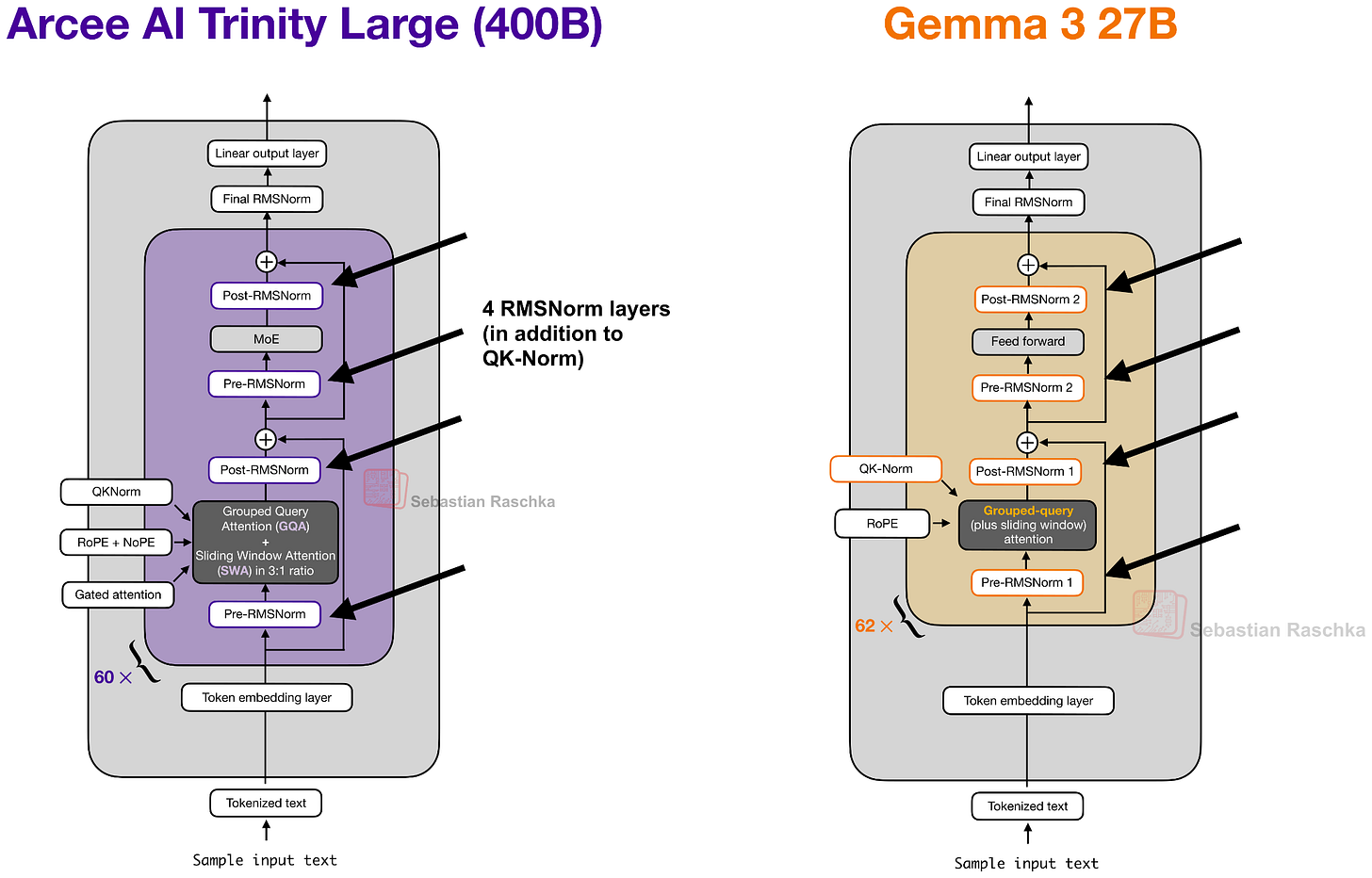
RMSNorm 深度缩放
Trinity 使用 4 个 RMSNorm 层(类似 Gemma 3),但有个巧妙的变化:第二个 RMSNorm 的增益初始化为 1 / sqrt(L)(L 为总层数)。训练早期残差更新幅度小,随着模型学到正确的缩放比例后逐渐增大。
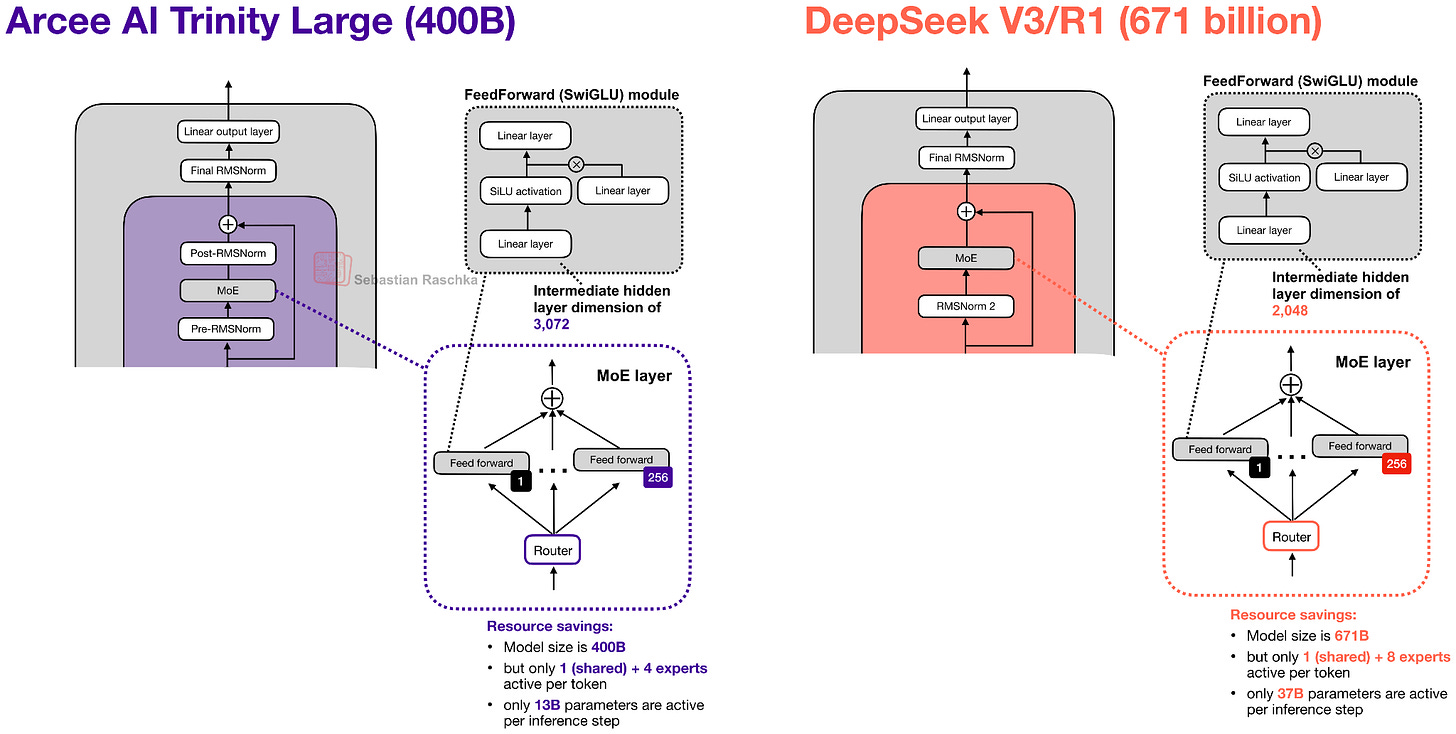
MoE 设计
MoE 采用 DeepSeek 风格(大量小专家),但做得更粗粒度以提高推理吞吐(Mistral 3 Large 采用 DeepSeek V3 架构时也做了同样的权衡)。
其他特点包括 QK-Norm(对 key 和 query 做 RMSNorm 以稳定训练)以及全局注意力层中不使用位置编码(NoPE),类似 SmolLM3。
2. Moonshot AI Kimi K2.5(1T, 1月27日)
同一天发布的 Kimi K2.5 是 1 万亿参数的巨兽,在发布时创下了开源模型的性能天花板,在自家基准上与当时领先的闭源模型持平。
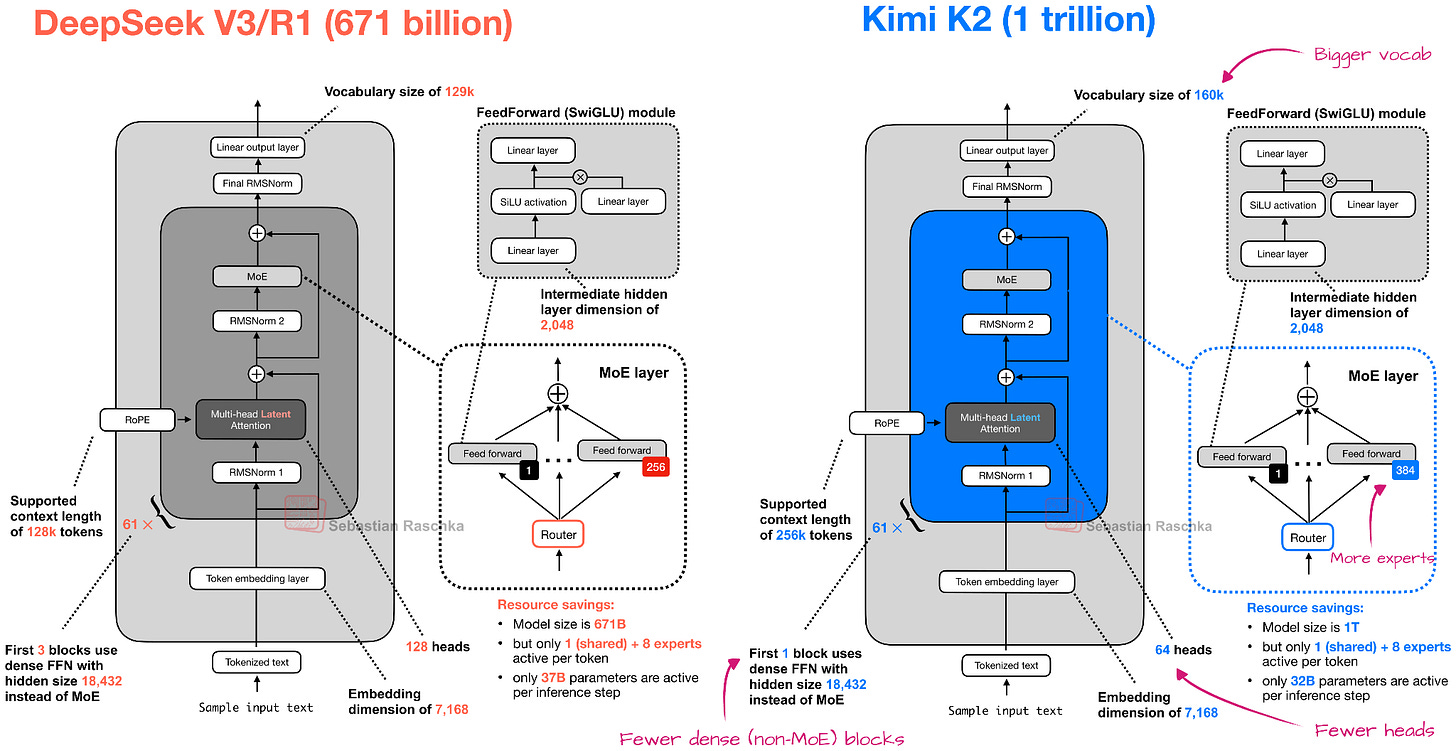
架构:放大版 DeepSeek V3
Kimi K2.5 本质上是 Kimi K2 的多模态升级,而 K2 本身是 DeepSeek V3 架构的放大版。
原生多模态:早期融合
K2 是纯文本模型,K2.5 增加了视觉支持。训练采用早期融合(early fusion)——在大约 15 万亿混合视觉和文本 token 上联合预训练,视觉 token 从预训练早期就和文本 token 一起输入。
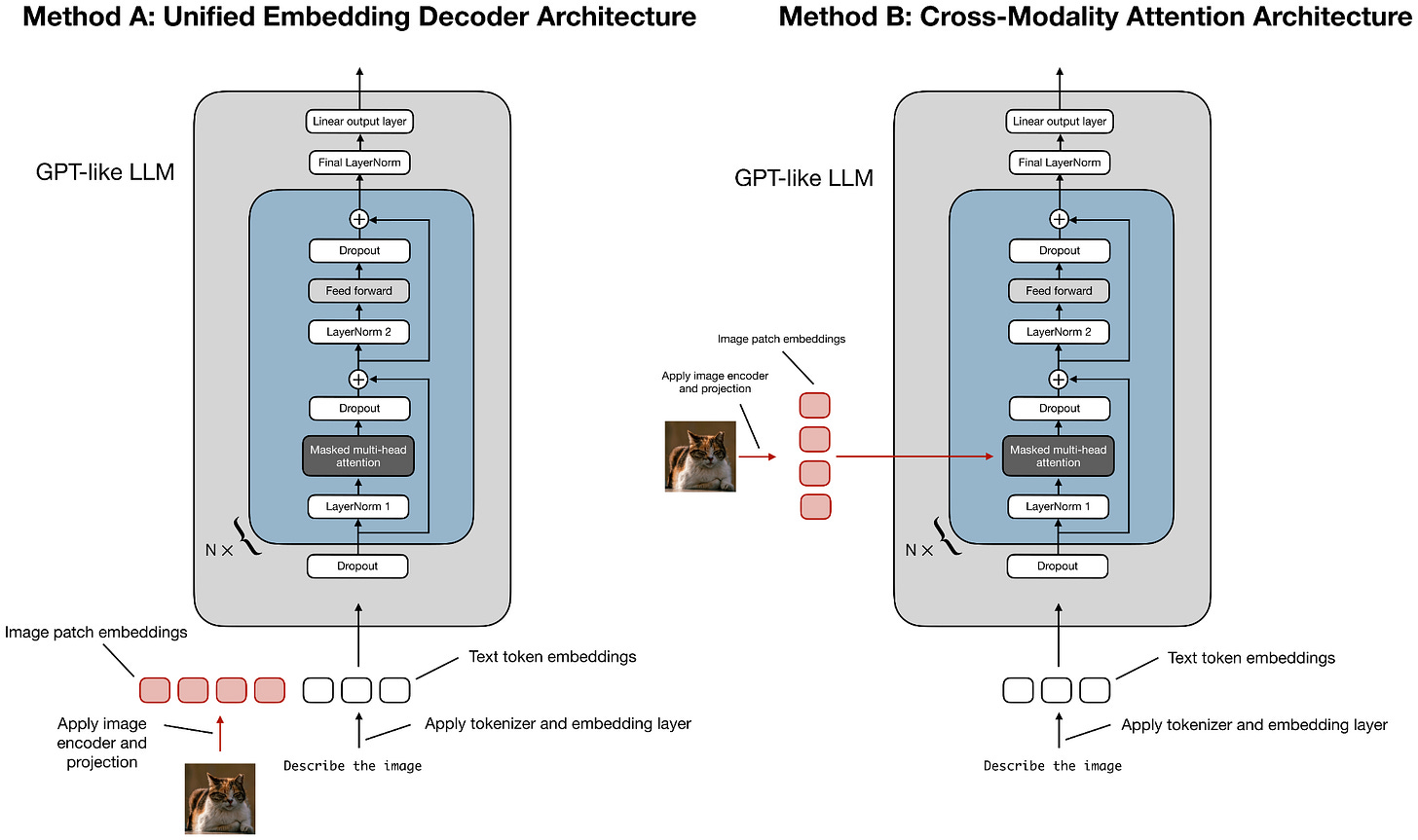
一个重要的消融实验显示:在预训练早期就引入少量视觉 token,效果优于后期引入大量视觉 token。即使总的视觉 token 数量相同,early exposure 的收益更大。
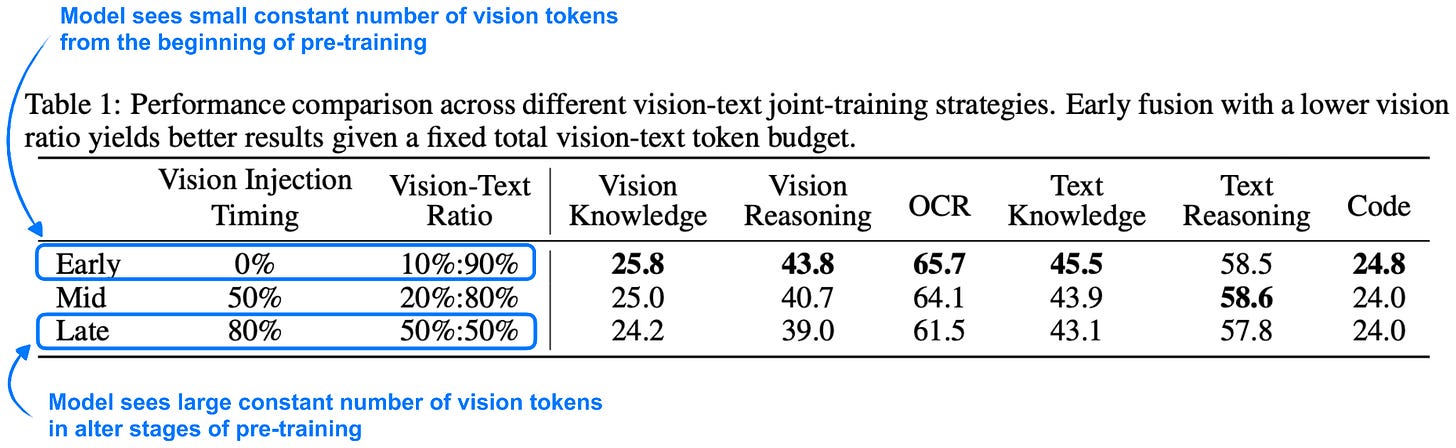
注意:“早期融合”在多模态论文中有两层含义:(1) 视觉 token 在预训练的什么阶段引入;(2) 视觉 token 如何与文本 token 结合(是作为 embedded token 并排输入,还是其他方式)。Kimi K2.5 两层含义都适用。
3. StepFun Step 3.5 Flash(196B, 2月1日)
Step 3.5 Flash 是本文中最”出人意料”的模型。196B 参数(11B 活跃)的它在建模性能上超过了 671B 的 DeepSeek V3.2(37B 活跃),推理速度更是 100 tokens/sec vs 33 tokens/sec(在 Hopper GPU 上)。
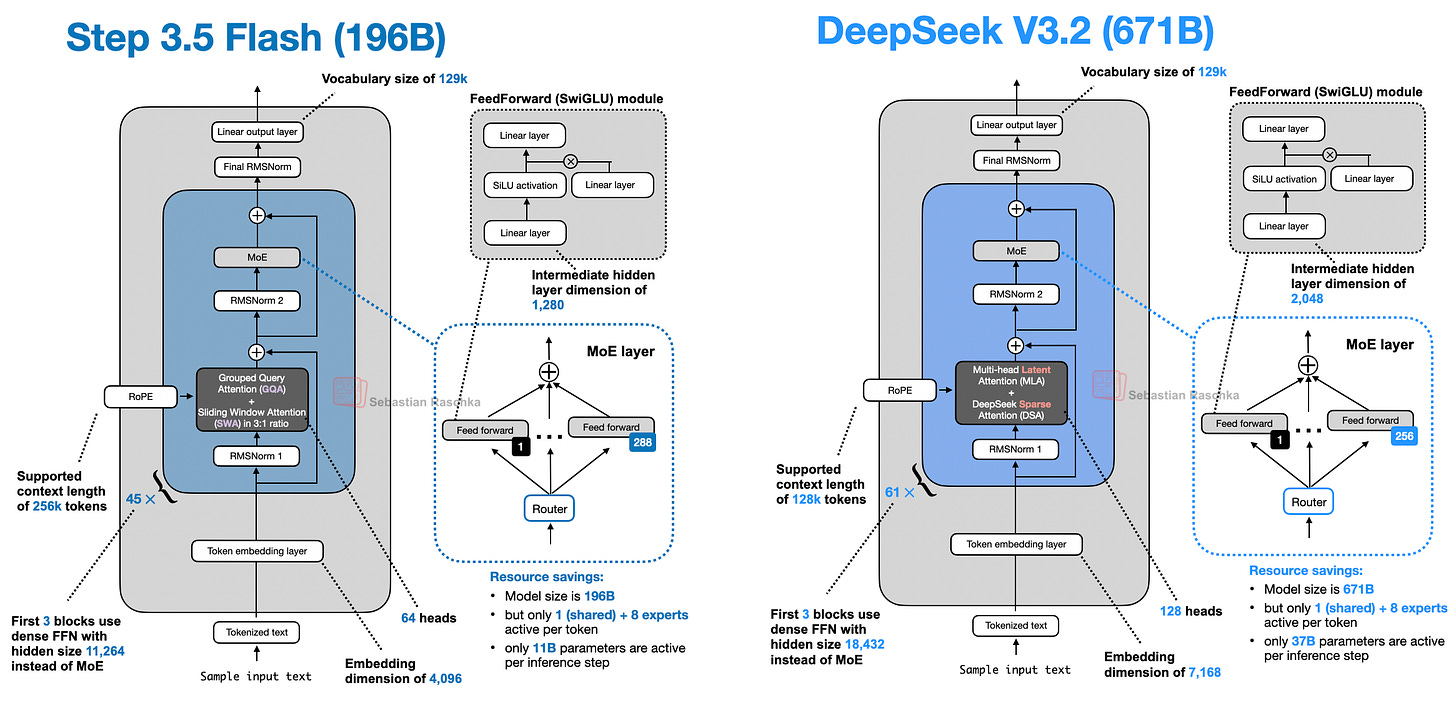
Multi-Token Prediction (MTP)
Step 3.5 Flash 高性能的一个关键原因是 MTP-3。MTP 的核心思想:训练 LLM 在每个位置 t 同时预测 t+1 到 t+k 个未来 token(通过小的额外 head),然后把这些位置的交叉熵损失求和。
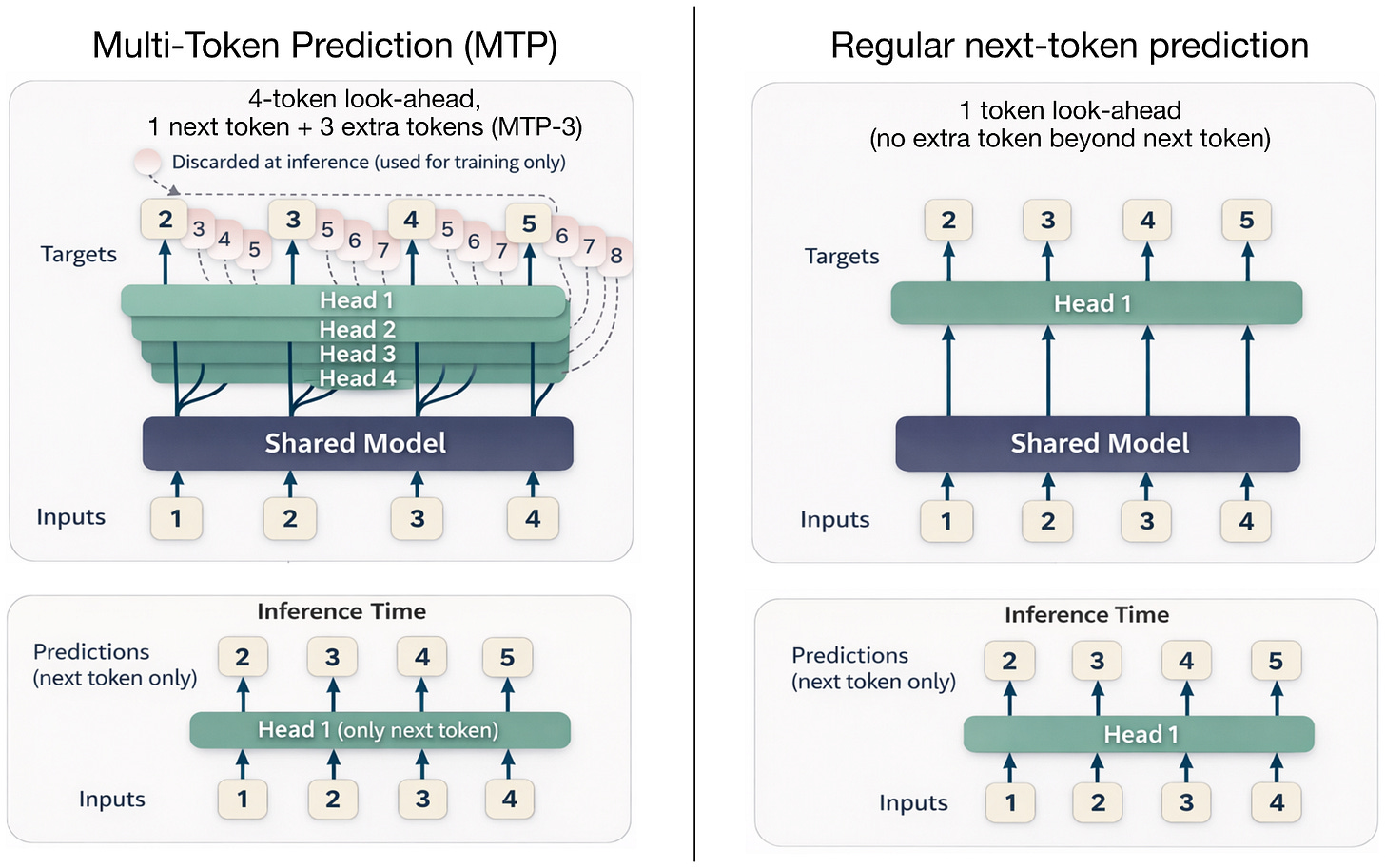
关键区别:
- DeepSeek V3:MTP-1(仅训练时预测 1 个额外 token),推理时可选
- Step 3.5 Flash:MTP-3(训练和推理都预测 3 个额外 token)——大多数模型推理时不用 MTP,这是个例外
- Trinity 和 Kimi K2.5:不使用 MTP
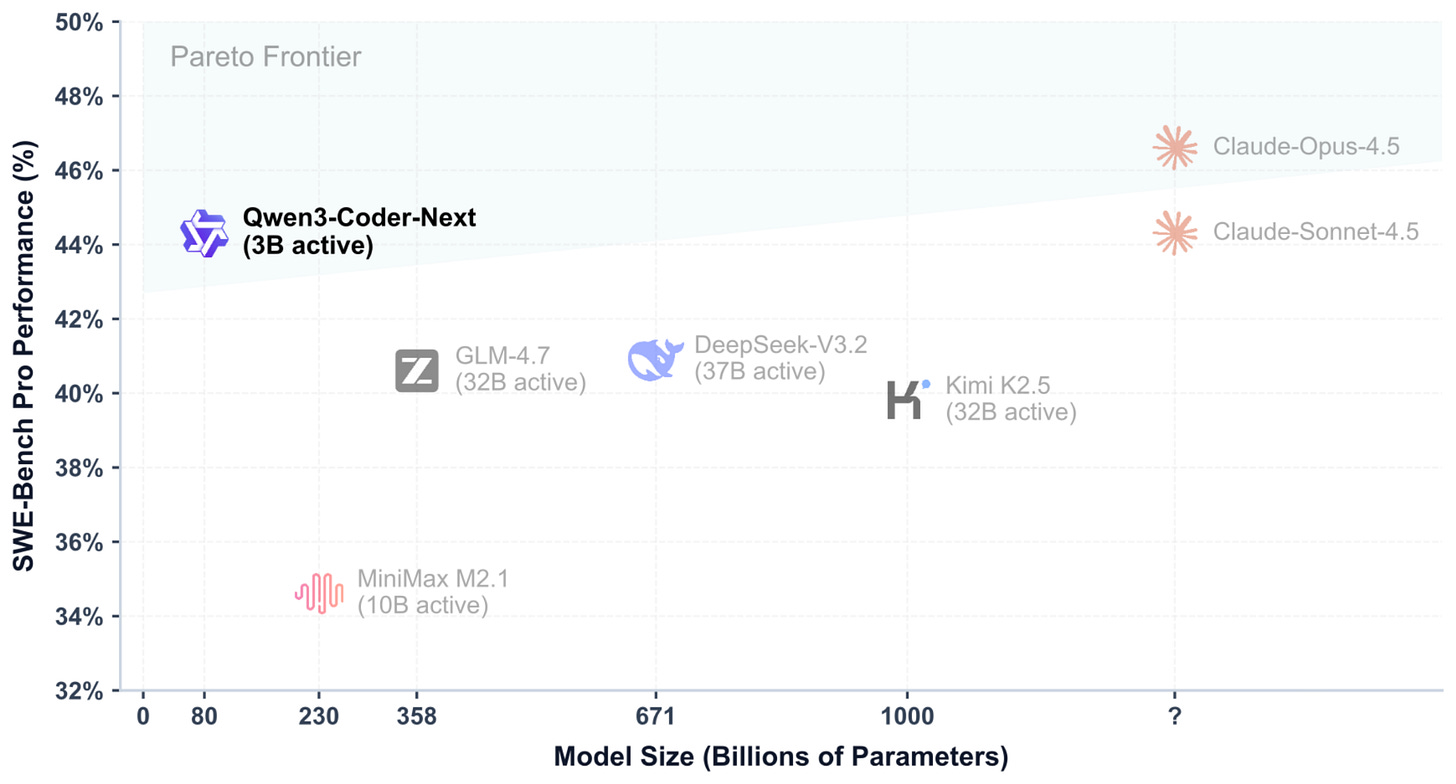
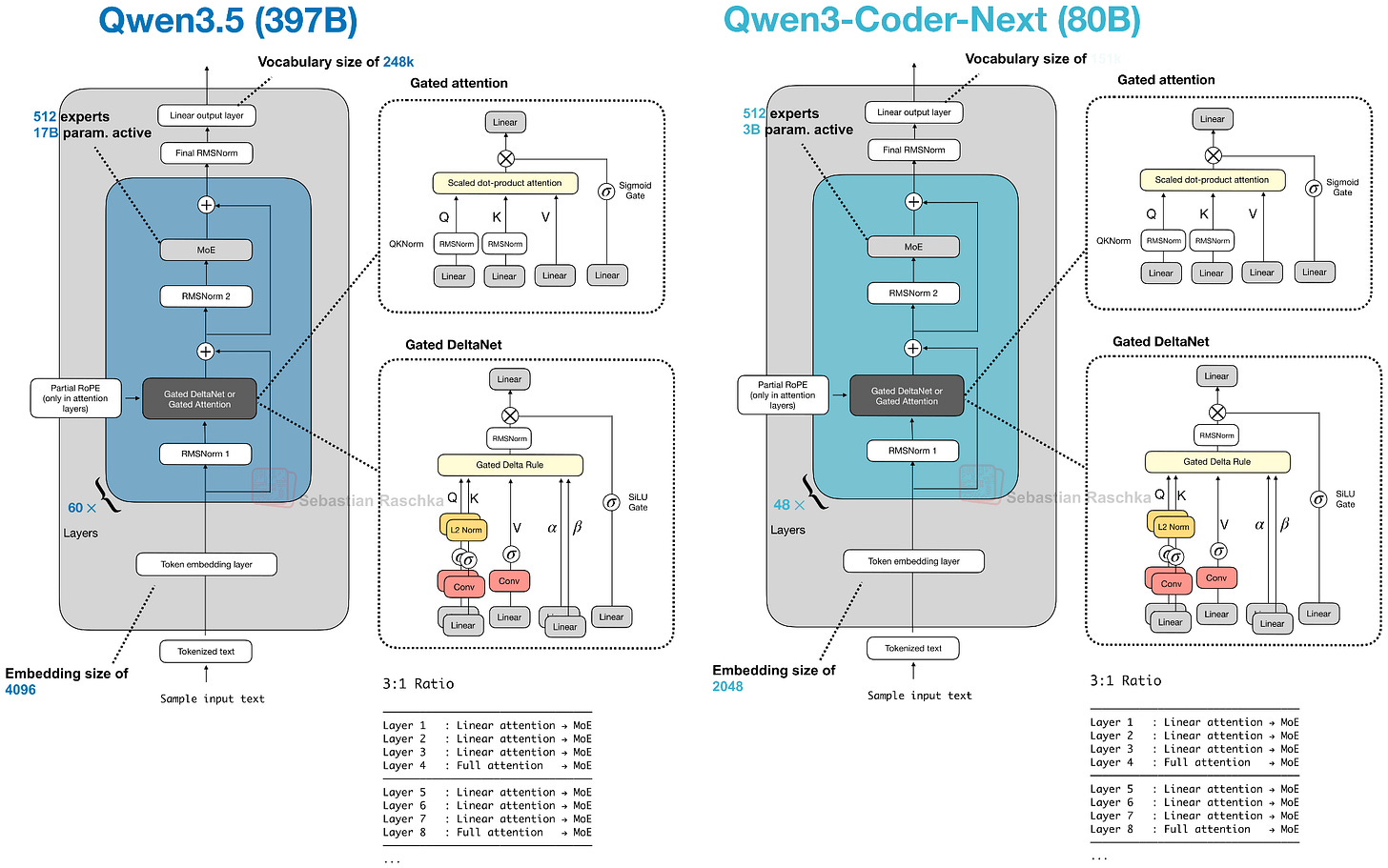
4. Qwen3-Coder-Next(80B, 2月3日)
Qwen3-Coder-Next 是 80B MoE 模型(仅 3B 活跃参数),但在编程任务上表现惊人——超过了 DeepSeek V3.2(37B 活跃)、Kimi K2.5 和 GLM-4.7(都是 32B 活跃),SWE-Bench Pro 性能甚至接近 Claude Sonnet 4.5。
用 ollama 在本地运行,大约需要 48.2 GB 存储和 51 GB 内存。
架构:Gated DeltaNet + Gated Attention 混合
Qwen3-Coder-Next 的底层架构就是 Qwen3-Next 80B,它引入了本文中最重要的架构创新之一——混合注意力机制。
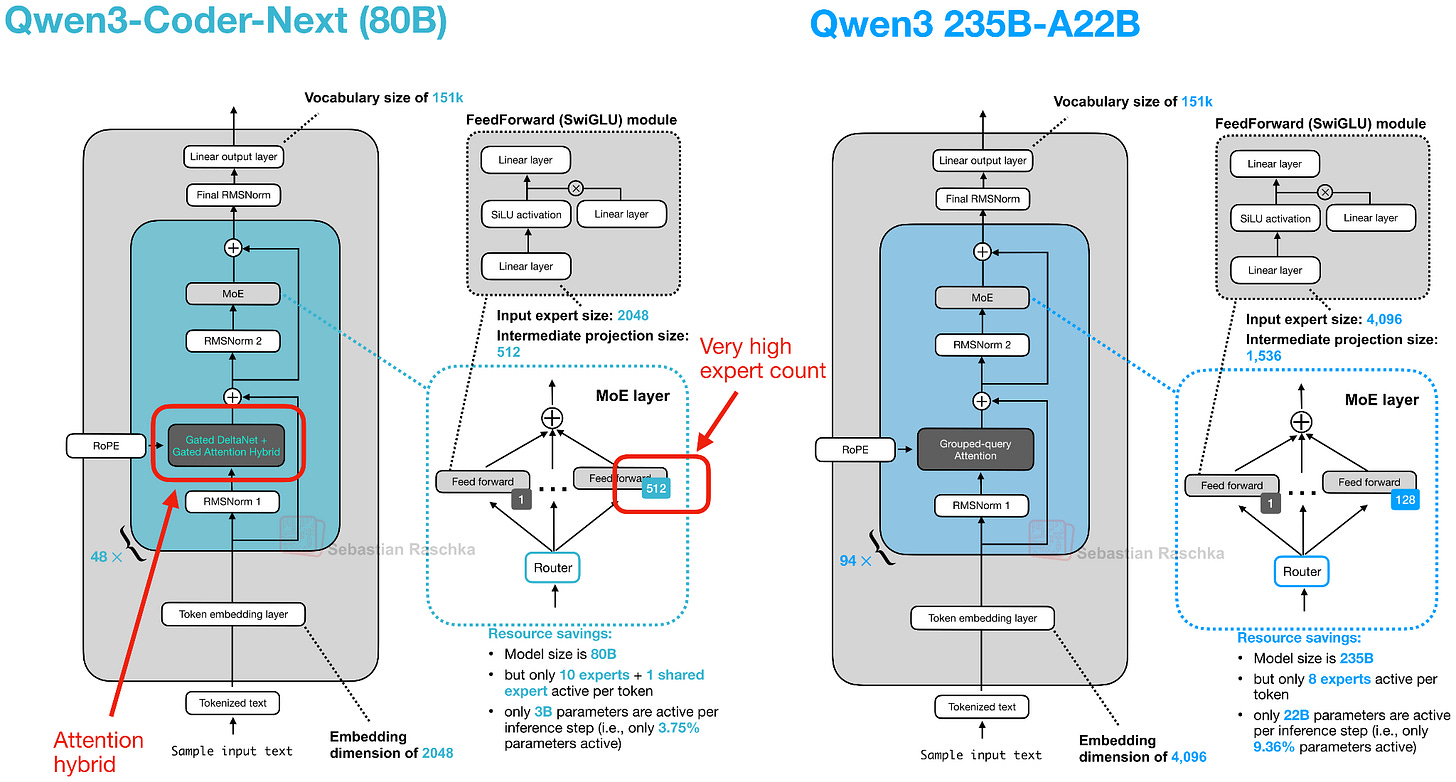
尽管比前代 235B 模型小 3 倍,Qwen3-Next 引入了 4 倍数量的专家,并加入了共享专家。更重要的是,它用 Gated DeltaNet + Gated Attention 混合替换了常规注意力,3:1 的比例配置使得原生支持 262k token 上下文长度(前代只有 32k 原生 / 131k 用 YaRN 扩展)。
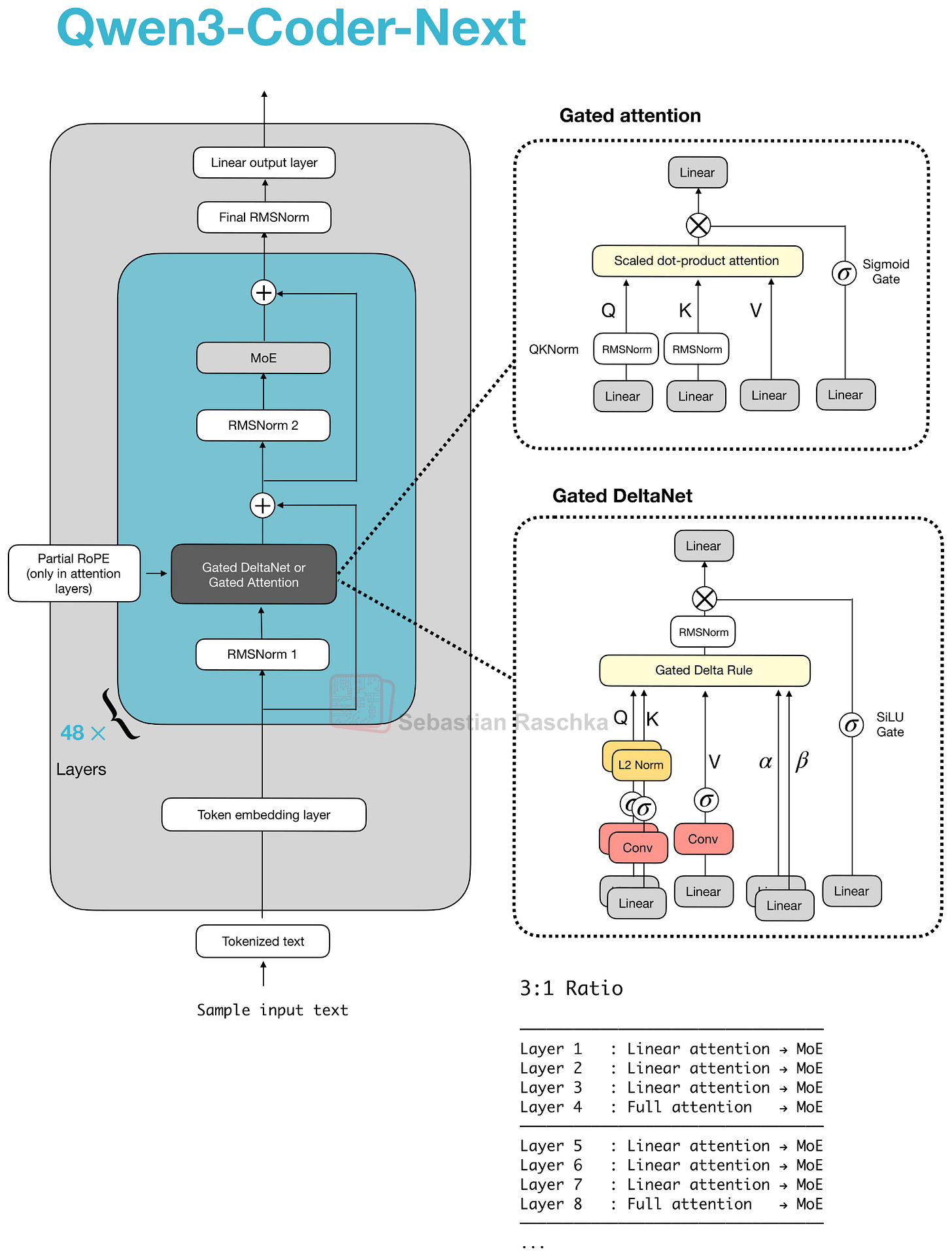
这个混合机制怎么理解?
Gated Attention 块(1/4 的层使用):本质上是 GQA 加了几个稳定性改进:
- sigmoid 输出门控,逐通道缩放注意力结果
- 零中心 RMSNorm(而不是标准 RMSNorm)做 QK-Norm
- 部分维度使用 RoPE
Gated DeltaNet 块(3/4 的层使用):更激进的变化。用快速权重 delta rule 更新替代了标准注意力。q, k, v 和两个门控(α, β)通过线性层和轻量卷积层生成。
DeltaNet 本质上是 Mamba 的替代方案——两者都属于”线性时间、无缓存”家族:
- Mamba:用状态空间滤波器(学习的动态卷积)维护状态
- DeltaNet:用 α 和 β 更新一个小的快速权重记忆,用 q 读取
代价是 DeltaNet 的内容检索精度不如全注意力,所以保留了 1/4 的 Gated Attention 层做补偿。
5. z.AI GLM-5(744B, 2月12日)
GLM-5 的发布是个大事件——在发布时它在基准上看起来与 GPT-5.2 extra-high、Gemini Pro 3、Claude 4.6 Opus 持平。
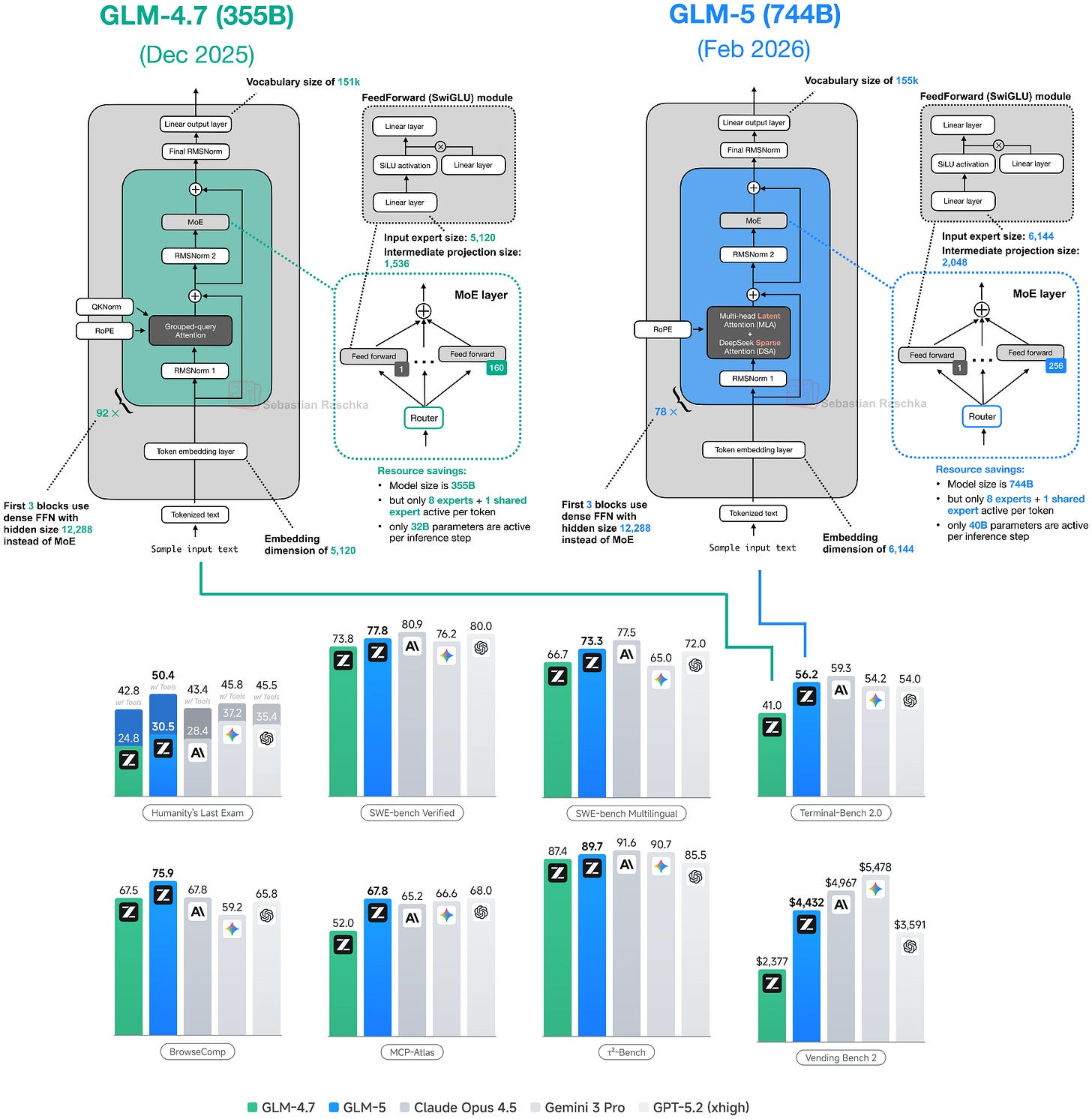
从 GLM-4.7 到 GLM-5 的主要变化:
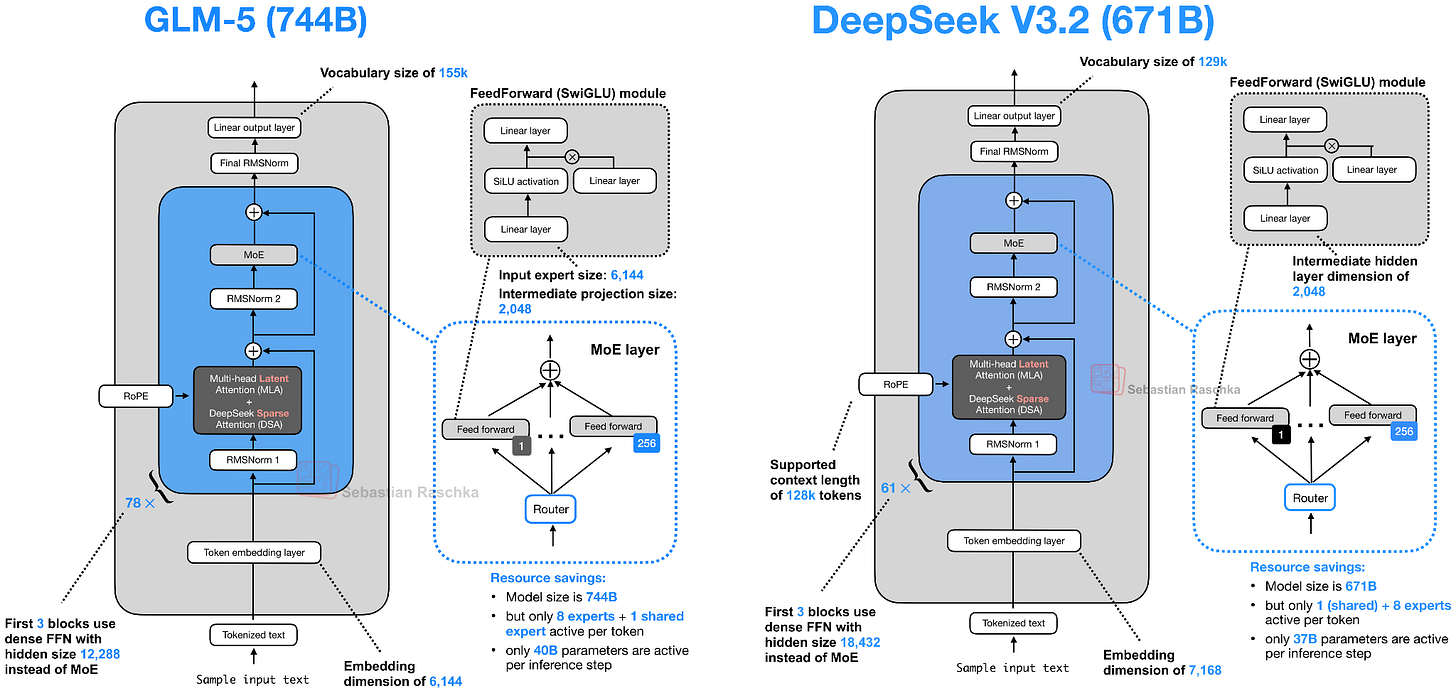
- 参数量从 355B 翻倍到 744B(介于 DeepSeek V3.2 的 671B 和 Kimi K2.5 的 1T 之间)
- 采用了 DeepSeek 的 MLA(多头潜在注意力) 和 DeepSeek 稀疏注意力,用于降低长上下文推理成本
- 专家数从 160 增加到 256,但每 token 的活跃专家数保持 8 个 + 1 个共享
- 嵌入维度从 5,120 增加到 6,144
- 层数反而从 92 减少到 78——减少串行依赖以降低推理延迟
尽管参数少 26%,GLM-5 在多数基准上略胜 Kimi K2.5:
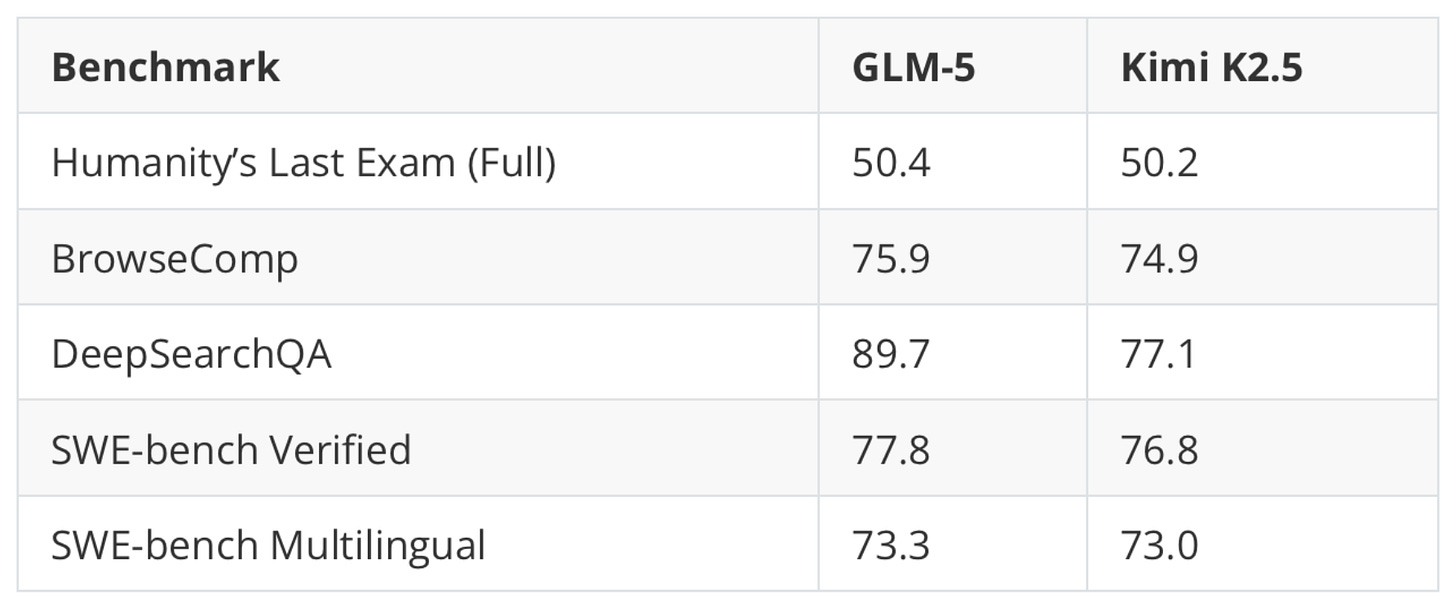
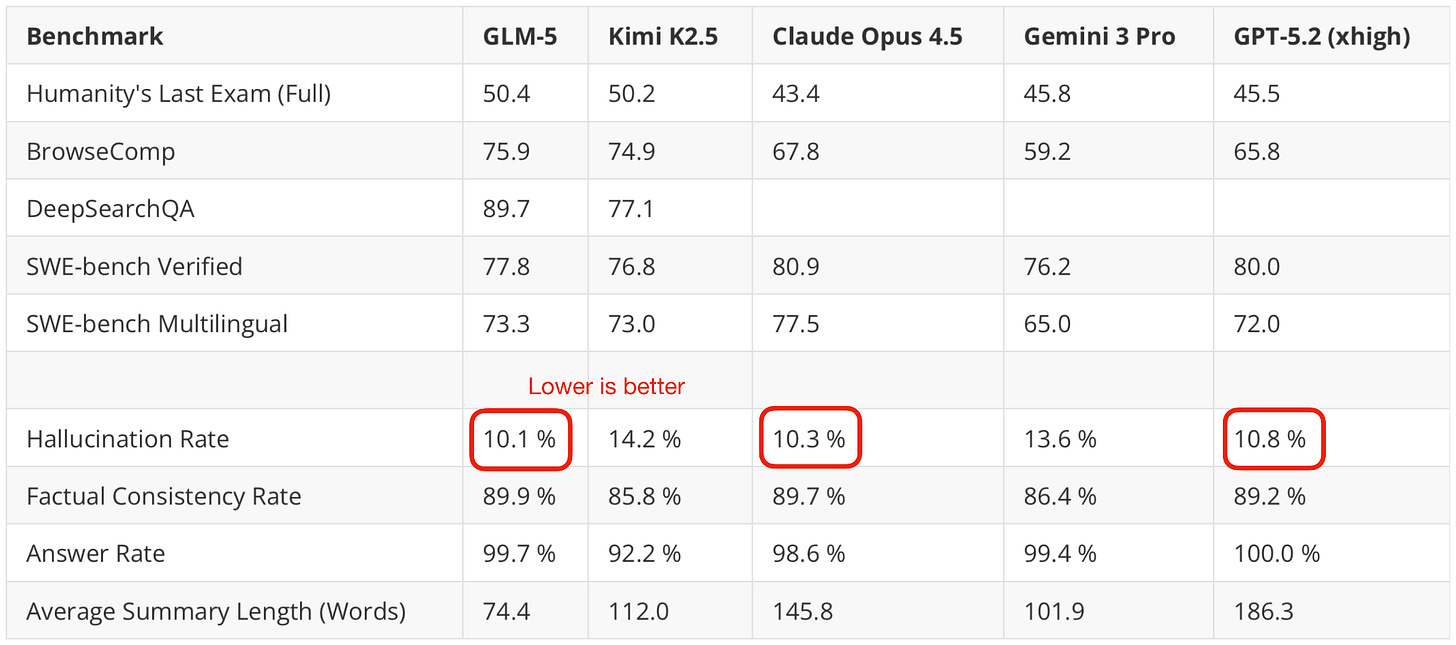
在独立的幻觉排行榜上,GLM-5 确实与 Opus 4.5 和 GPT-5.2 持平:
6. MiniMax M2.5(230B, 2月12日)
虽然 GLM-5 和 Kimi K2.5 名声更大,但在 OpenRouter 的实际使用量上,MiniMax M2.5 远超它们。
在 SWE-Bench Verified 编程基准上,M2.5 甚至略强于 GLM-5:
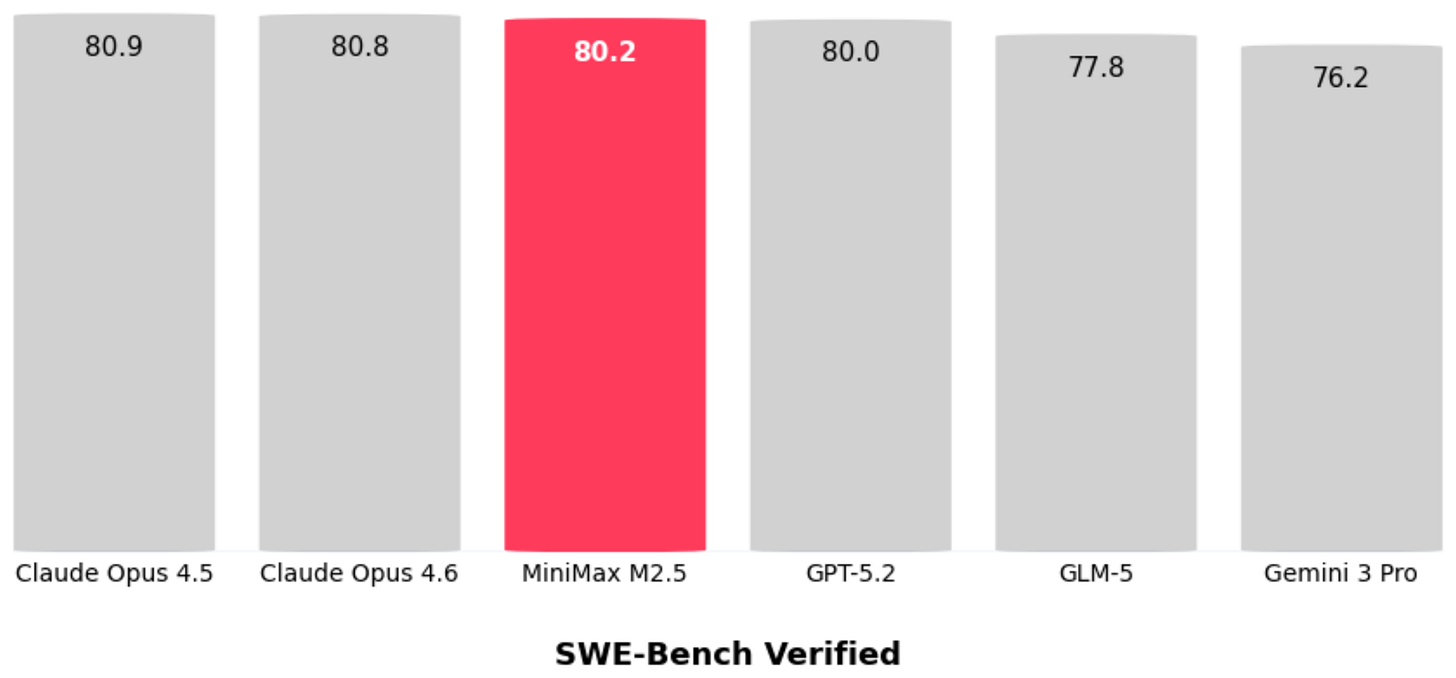
Raschka 在这里插了一个重要的旁注:Opus 4.5 和 Opus 4.6 在 SWE-Bench Verified 上几乎得分一样。这不是说 LLM 进步停滞了——更可能是 SWE-Bench Verified 已经饱和。OpenAI 也专门写了文章 “Why SWE-bench Verified no longer measures frontier coding capabilities” 来说明这个问题。
架构:最经典的选择
M2.5 是 230B 参数模型,架构非常经典——只用了 Grouped Query Attention,没有滑动窗口、没有 MLA、没有其他效率优化。
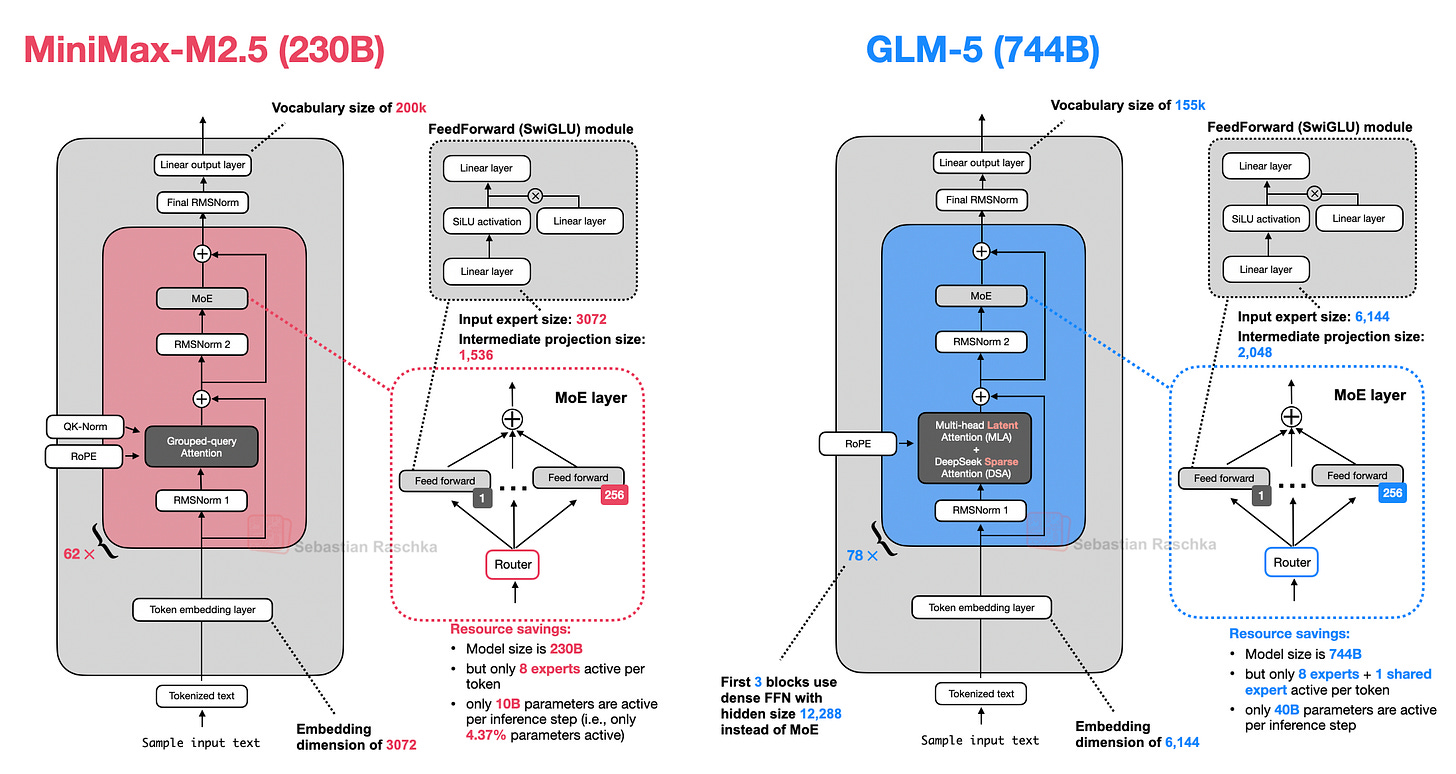
M2.5 的流行可能更多归因于性价比——比 GLM-5 小 4 倍但性能相近。
7. Nanbeige 4.1 3B(2月13日)
切换到小模型赛道。Nanbeige 4.1 3B 瞄准的是 Qwen3 在本地设备上的统治地位。
Qwen 系列模型的被使用程度有多广?看看 HuggingFace 上基于各家模型做 finetune 的模型数量就知道:
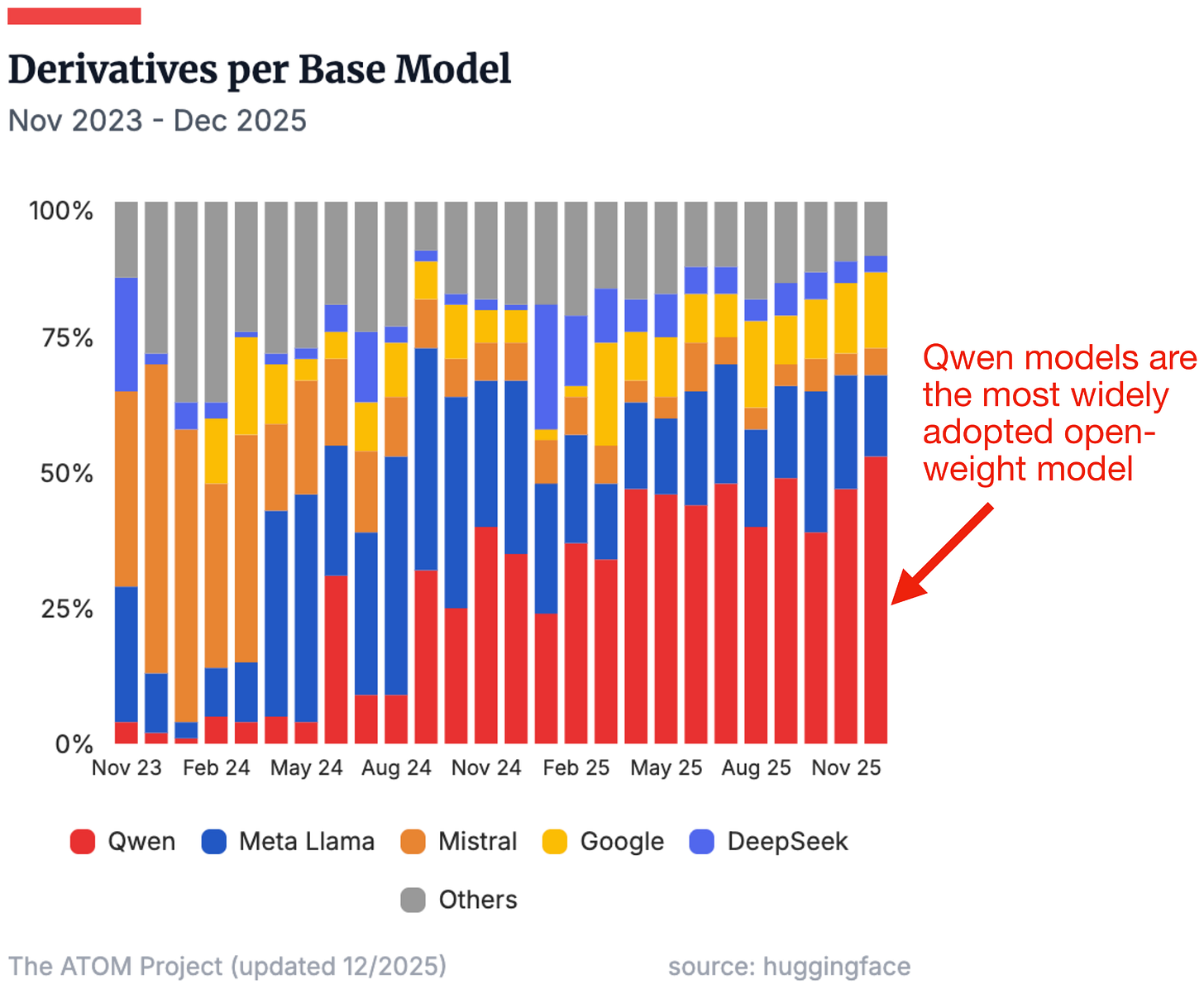
架构上,Nanbeige 4.1 3B 类似于 Qwen3 4B 和 Llama 3.2 3B,区别很小:
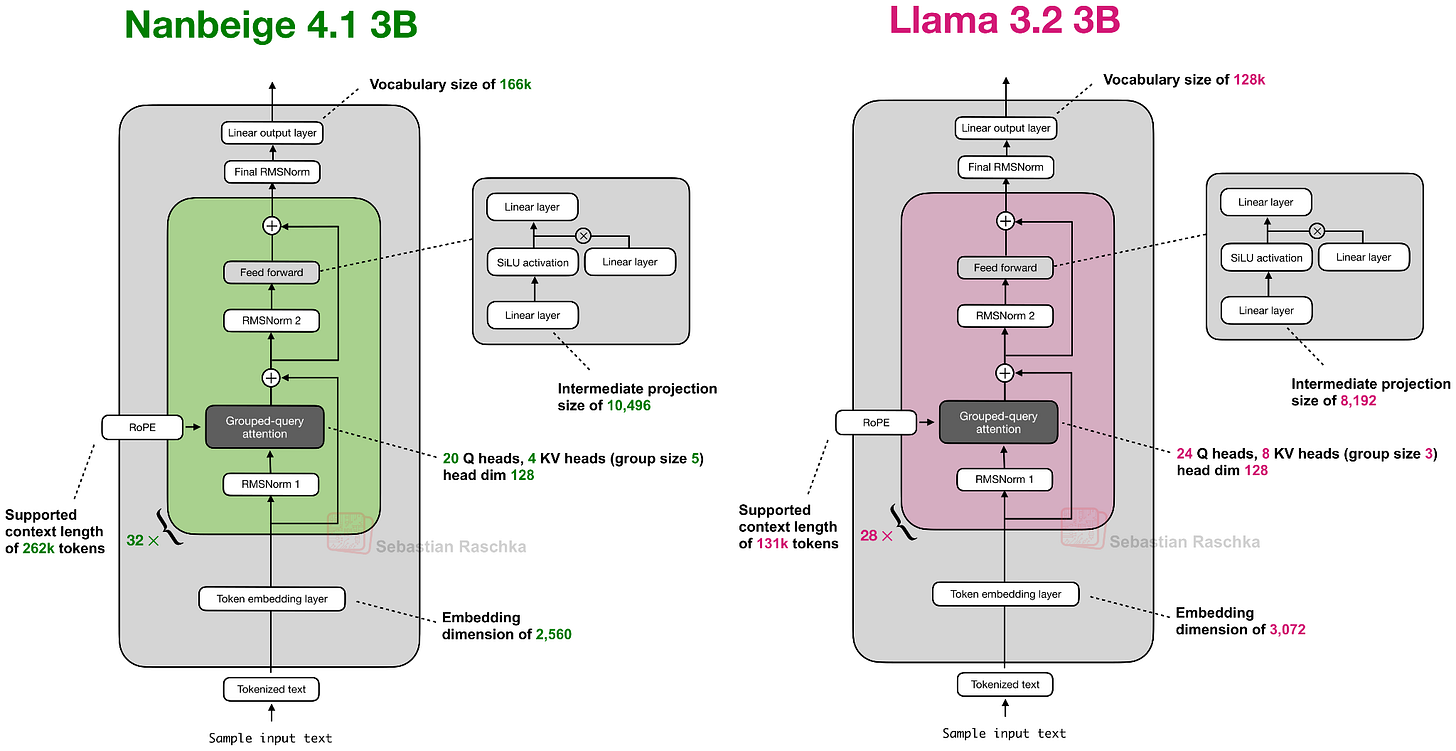
一个值得注意的细节:Nanbeige 没有做权重共享(weight tying,即输入 embedding 和输出层共享权重)。Raschka 指出,根据他的经验,权重共享虽然能减少参数量,但几乎总是导致更差的训练和验证损失。
8. Qwen3.5(397B, 2月15日)
Qwen3.5 397B-A17B 是 Qwen 系列的重大升级,超过了此前未开源的 Qwen3-Max(1T),尤其在 agentic terminal coding 方面。
架构意义:混合注意力进入主线
最重要的信号:Qwen3.5 正式采用了 Qwen3-Next 的混合注意力架构(Gated DeltaNet + Gated Attention)。这意味着混合注意力不再是实验分支,而是被纳入了主线产品。
除了扩大模型规模,Qwen3.5 还加入了多模态支持(此前只在独立的 Qwen3-VL 中提供)。后续还发布了更小的版本:Qwen3.5-27B、Qwen3.5-35B-A3B、Qwen3.5-122B-A10B。
9. Ant Group Ling 2.5 / Ring 2.5(1T, 2月16日)
蚂蚁集团的 Ling 2.5(及推理变体 Ring 2.5)也是万亿参数级别,同样采用混合注意力架构,但用的是 Lightning Attention(而不是 Gated DeltaNet),并且采用了 DeepSeek 的 MLA。
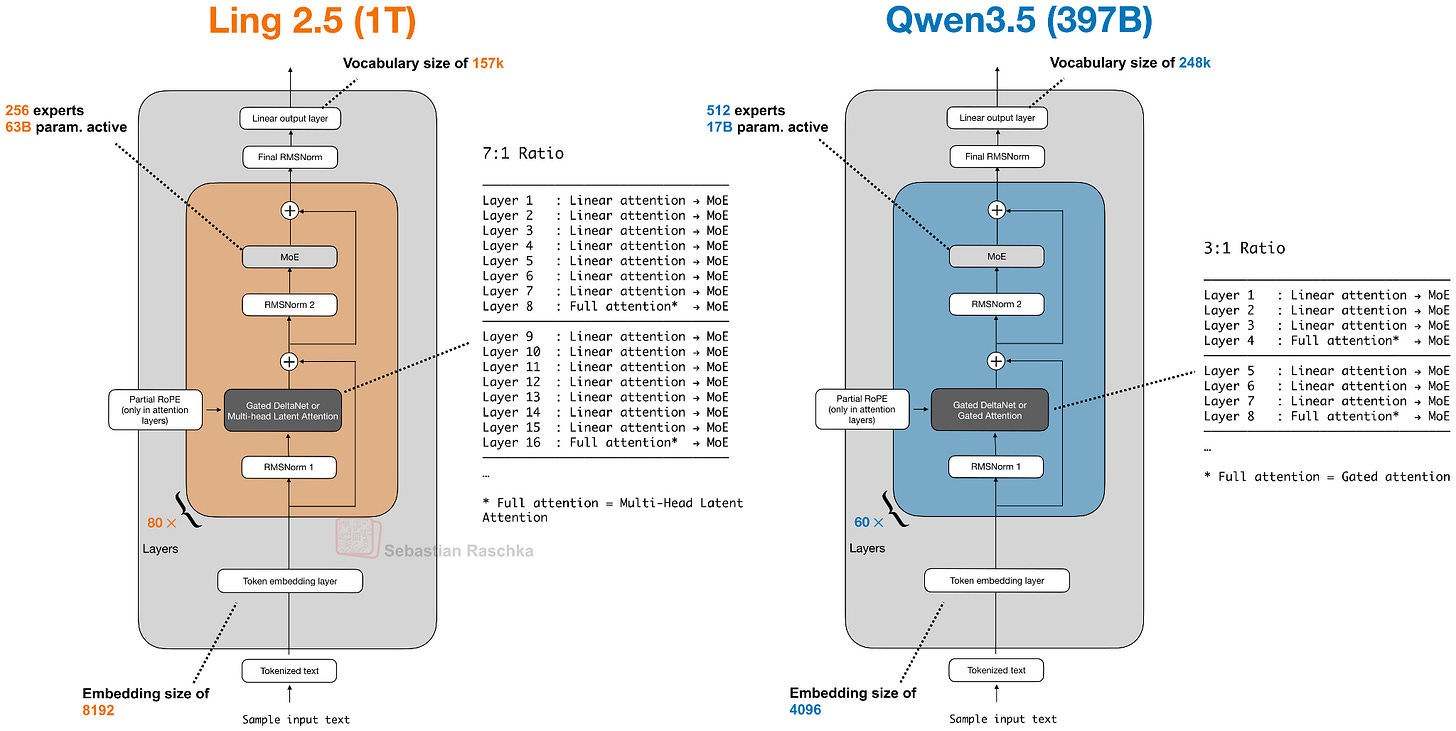
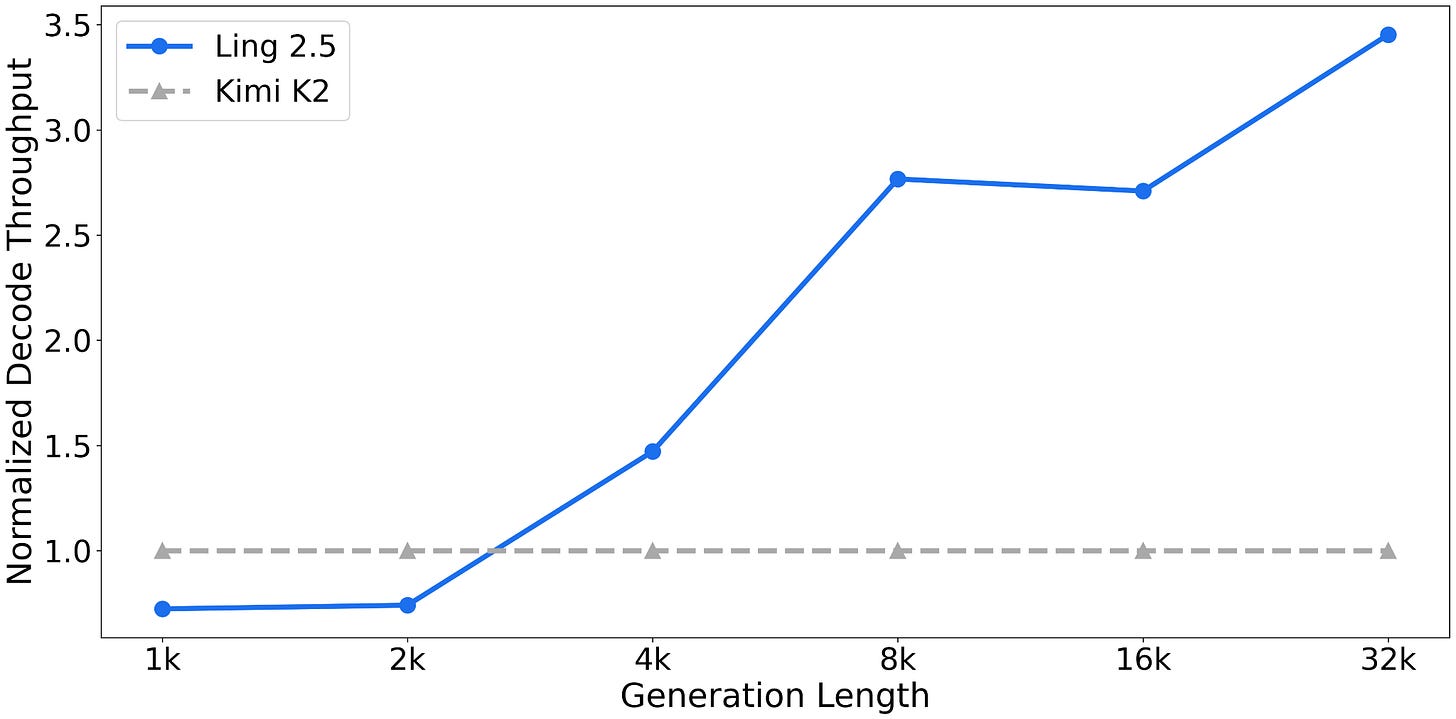
Ling 2.5 的卖点不是绝对性能,而是长上下文效率。与同为 1T 参数的 Kimi K2 相比,在 32k 序列长度下实现了 3.5 倍的吞吐量:
10. Cohere Tiny Aya(3.35B, 2月17日)
Tiny Aya 定位为”3B 参数级别最强的多语言开源模型”(超过 Qwen3-4B、Gemma 3 4B、Ministral 3 3B),支持多种语言和地区变体。
并行 Transformer 块
Tiny Aya 最有趣的架构特点是并行 Transformer 块:attention 和 MLP 从同一个归一化输入并行计算,然后一步加回残差。这减少了层内串行依赖,提高计算吞吐。
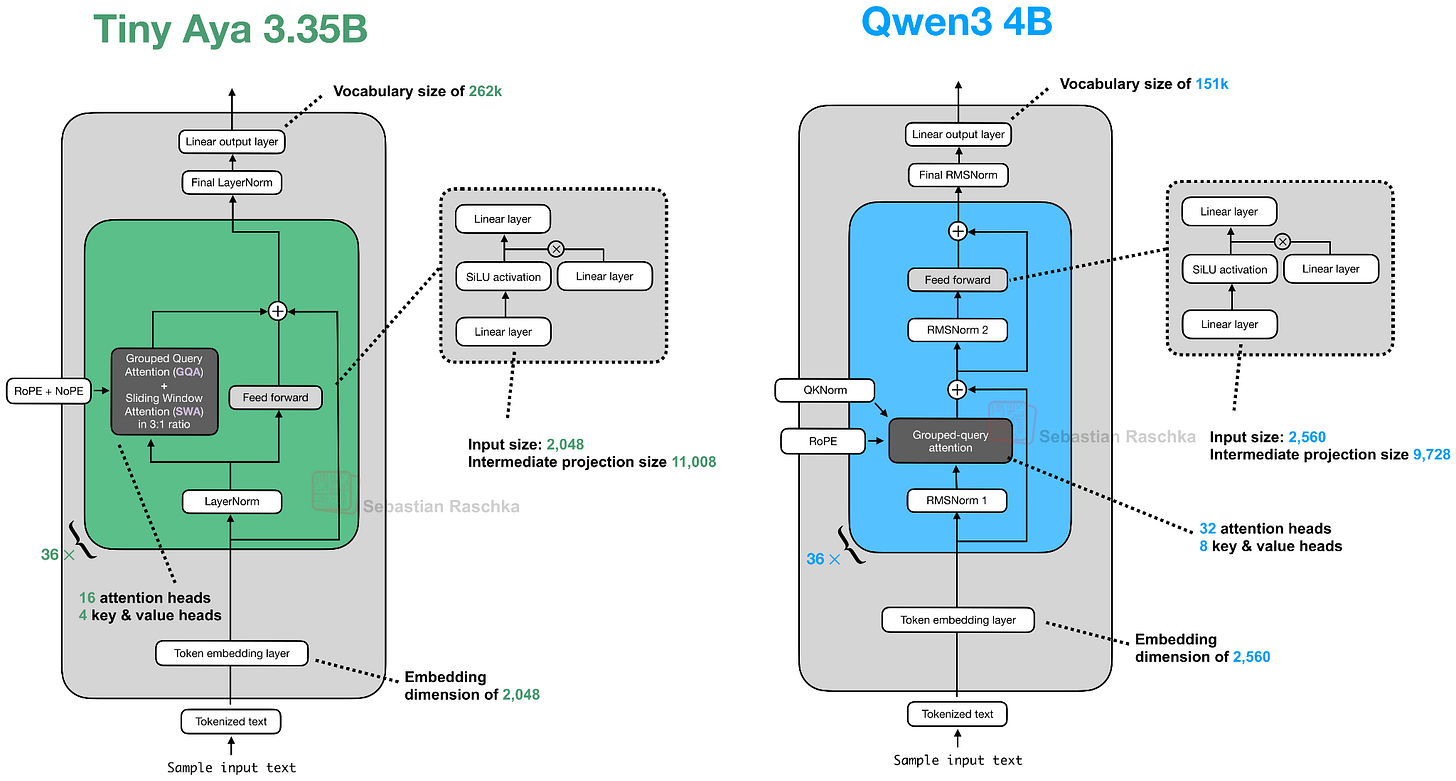
一个有趣的细节:Tiny Aya 去掉了 QK-Norm。开发者的解释是 QK-Norm 会影响长上下文性能——这与大多数模型加入 QK-Norm 的趋势相反。
Raschka 觉得并行 Transformer 块很有意思,专门做了一个 from-scratch 实现。
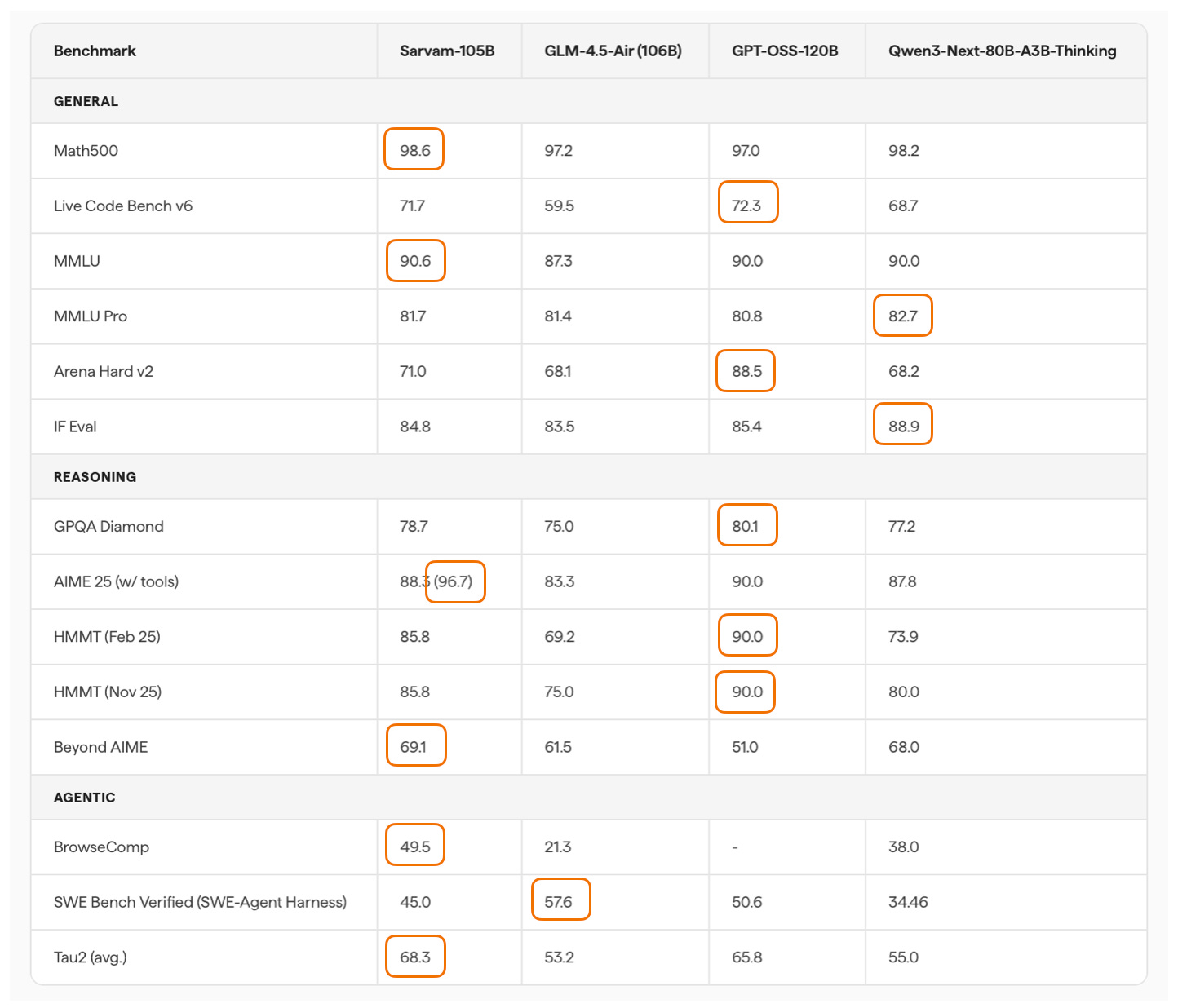
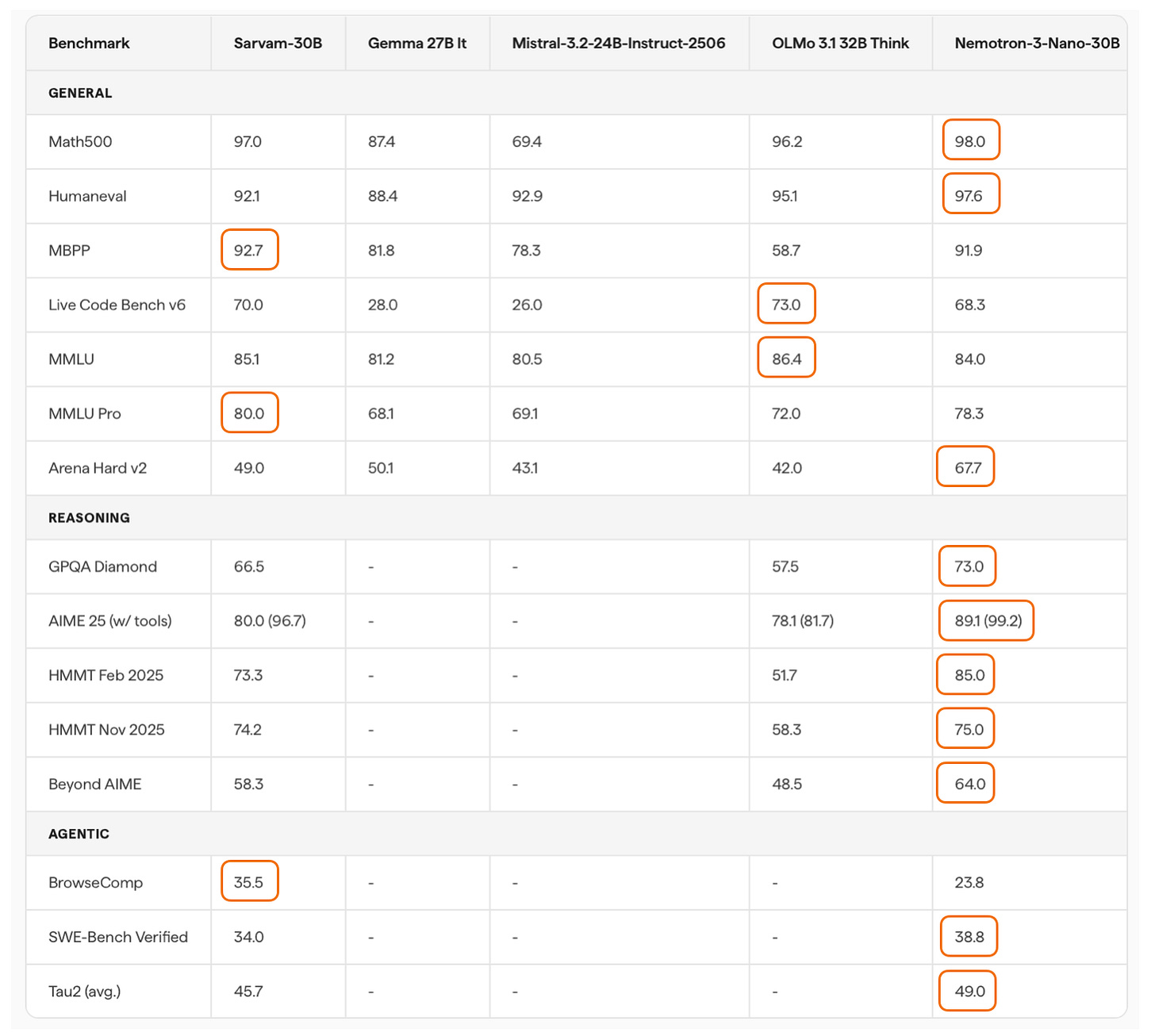
更新:Sarvam 30B & 105B(3月6日)
来自印度的 Sarvam 是一个令人惊喜的发布。两个版本的架构选择很有意思:30B 用经典 GQA,105B 切换到 DeepSeek 的 MLA。
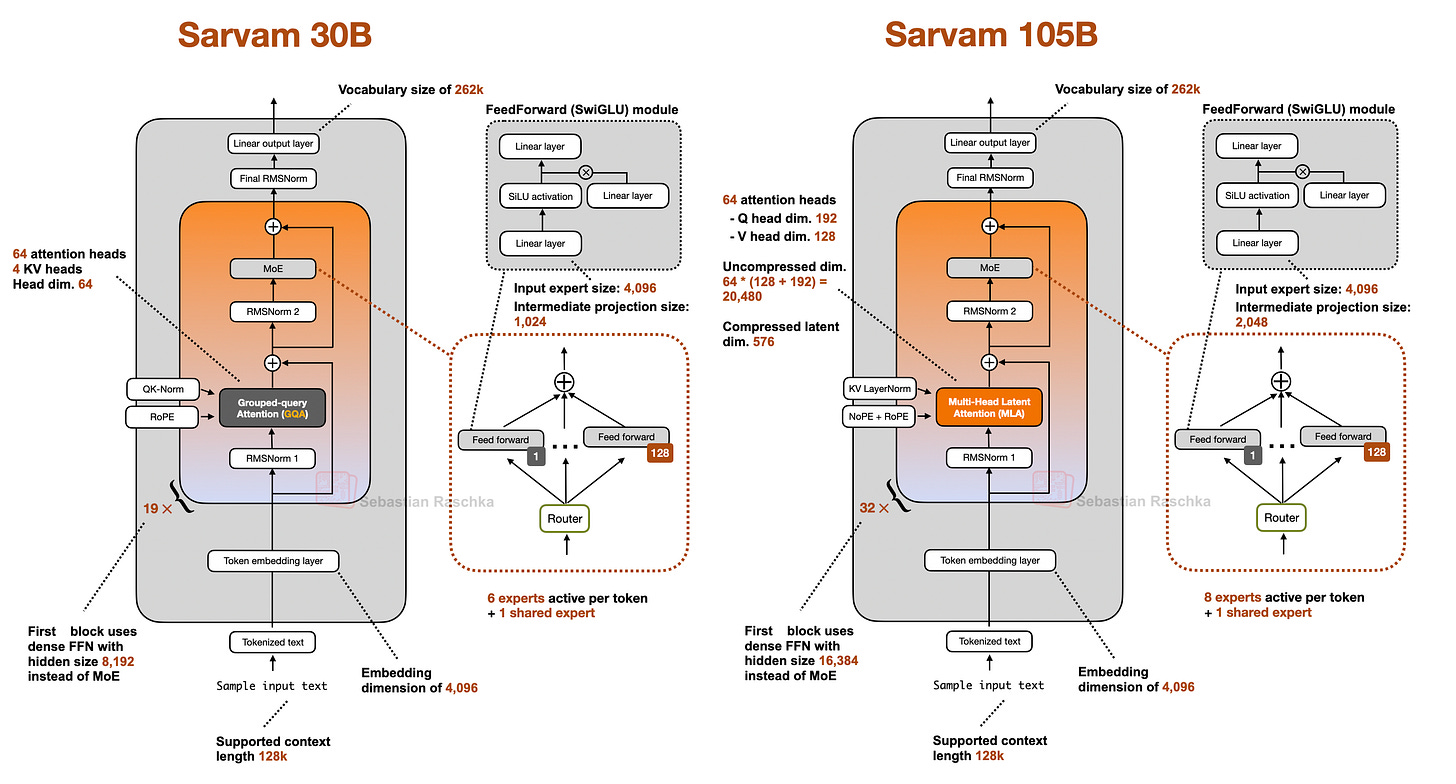
GQA 和 MLA 的效率对比:
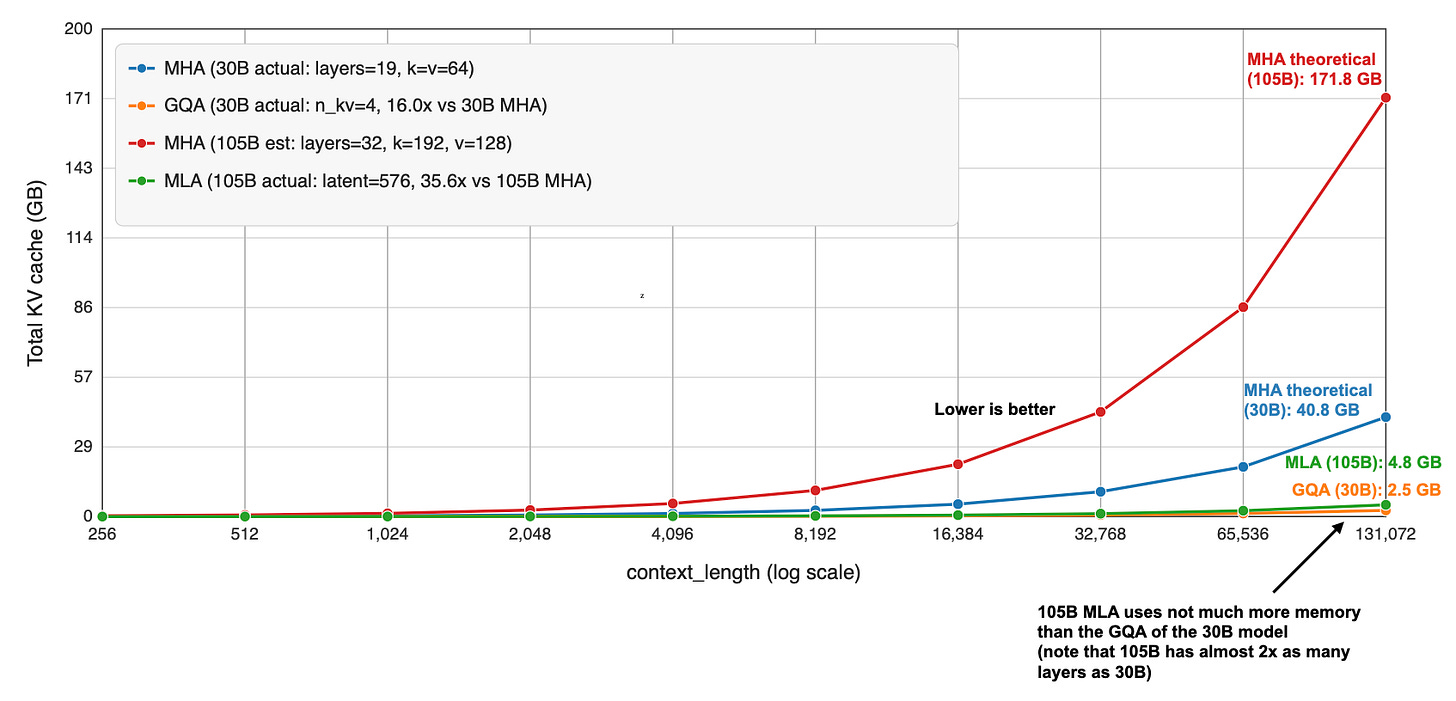
105B 模型的 agentic reasoning (Tau2) 甚至超过了 DeepSeek R1 0528。而 Sarvam 在印度语言上更是碾压级别——90% 的时间被偏好,token 效率高 4 倍。
架构趋势总览
Raschka 在文末总结了所有模型使用的注意力类型:
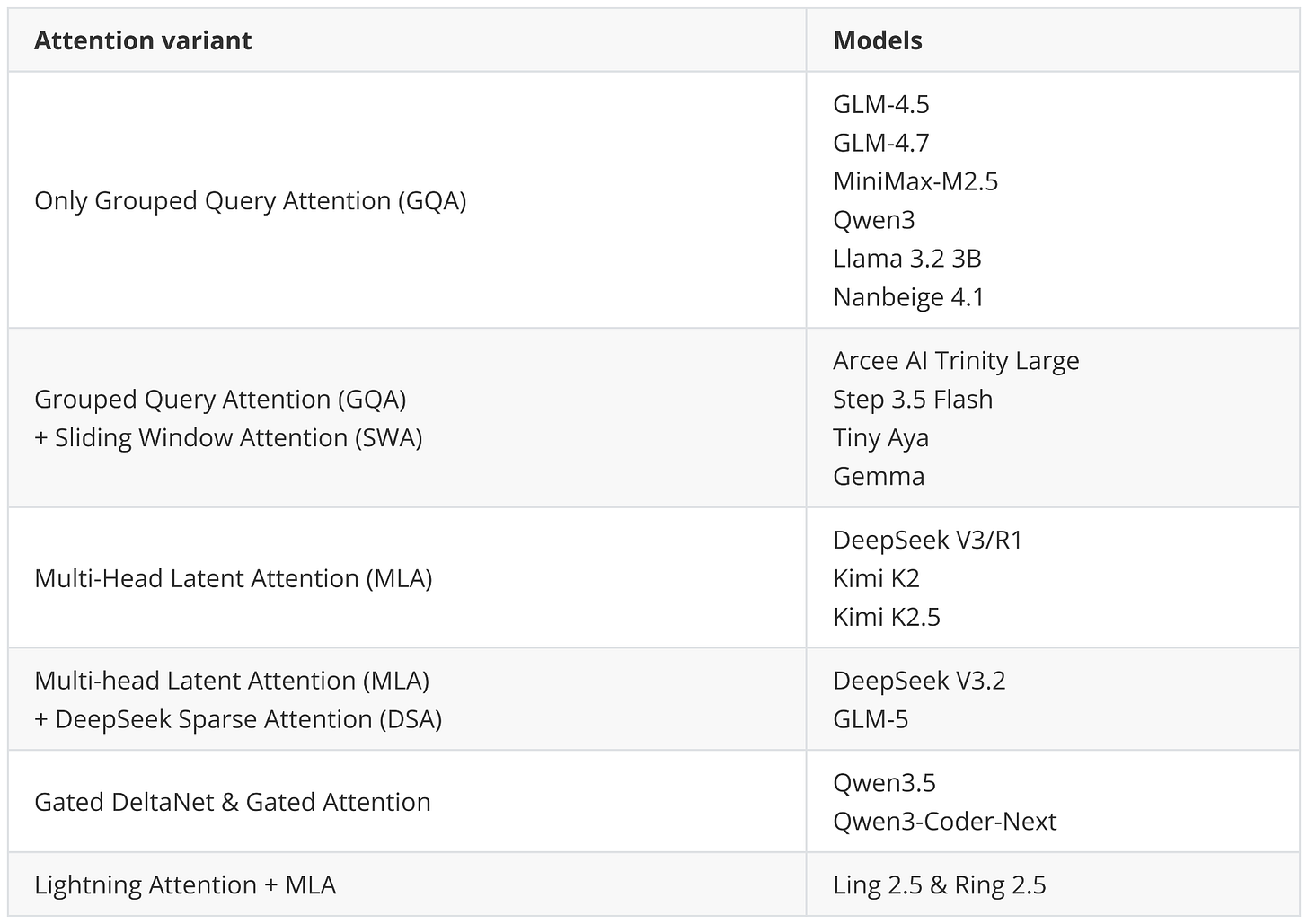
四大趋势
1. DeepSeek 成为架构标准 MoE、MLA、稀疏注意力——DeepSeek V3 的设计被广泛借鉴。GLM-5 甚至同时采用了 MLA 和 DeepSeek 稀疏注意力。
2. 混合注意力从实验走向主流 Qwen 团队的路线最能说明问题:Qwen3-Next 作为实验分支引入 Gated DeltaNet,仅几个月后就正式纳入主线 Qwen3.5。Ling 2.5 用 Lightning Attention 做类似的事。纯全注意力的时代正在结束。
3. 小而强的模型越来越多 Step 3.5 Flash(196B)超过 DeepSeek V3.2(671B),Qwen3-Coder-Next(3B 活跃)接近 Claude Sonnet 4.5。效率优化(MTP、MoE、混合注意力)使得更小的模型可以匹敌甚至超越更大的模型。
4. 经典设计仍然有效 MiniMax M2.5 和 Nanbeige 4.1 只用了最基本的 GQA,没有任何花哨的效率优化,照样很受欢迎。Raschka 也指出,建模性能可能更多归因于数据质量和训练流程,而非架构本身。
| 技术组件 | 采用的模型 |
|---|---|
| MoE(混合专家) | Trinity, Kimi K2.5, Step 3.5, Qwen3-Next, GLM-5, Qwen3.5 |
| MLA(多头潜在注意力) | GLM-5, Ling 2.5, Sarvam 105B |
| Gated DeltaNet | Qwen3-Next, Qwen3.5 |
| Lightning Attention | Ling 2.5 |
| 滑动窗口注意力 | Trinity, Step 3.5 Flash |
| Gated Attention | Trinity, Qwen3-Next, Step 3.5 Flash |
| Multi-Token Prediction | Step 3.5 Flash (MTP-3) |
| QK-Norm | Trinity, Qwen3-Next(Tiny Aya 去掉了) |
| 并行 Transformer 块 | Tiny Aya |
| 经典 GQA(无其他优化) | MiniMax M2.5, Nanbeige 4.1, Sarvam 30B |
批判性分析
文章优势:
- 目前最全面的开源 LLM 架构横评,每个模型都有手绘架构对比图
- 技术层次清晰:不是简单罗列参数,而是解释每个架构选择的原因和 trade-off
- 交叉引用做得好,每个技术概念都链接到详细解释
值得注意的局限:
- 基准测试主要来自各团队自报数据,缺少统一独立评测
- SWE-Bench Verified 已经饱和(OpenAI 专门写了文章说明),但文中仍大量使用
- 训练数据和训练流程的讨论几乎没有——Raschka 自己也承认这才是性能差异的主因
- 缺少推理成本的系统性对比(不同模型在相同硬件上的 cost/token)
独立观察: 开源 LLM 的架构创新周期已经从”年”缩短到”月”。Qwen 的路线最能说明问题——Qwen3-Next 作为实验分支引入 Gated DeltaNet,仅几个月后就并入主线 Qwen3.5。对于想部署开源模型的团队来说,架构选型的窗口期正在急剧缩短。
延伸阅读
- LLM Architecture Gallery — 所有模型架构图和 fact sheet 的集中展示
- The Big LLM Architecture Comparison — 前作,覆盖更早期的模型
- Beyond Standard LLMs — Gated DeltaNet 和 Qwen3-Next 的详细解释
- From DeepSeek V3 to V3.2 — DeepSeek 稀疏注意力的技术细节
- Understanding Multimodal LLMs — 多模态 LLM 的融合方式解析